
Big Data revolutioniert die Fahrzeugmarktanalyse durch den Einsatz riesiger Datenmengen aus strukturierten und unstrukturierten Quellen wie Verkaufsanzeigen, Suchanfragen und Bildern. Neueste Machine-Learning-Modelle erreichen eine Prognosegenauigkeit von bis zu R² = 0,95, weit über herkömmlichen Methoden. Beispiele zeigen, wie neuronale Netzwerke und NLP-Techniken präzise Preisvorhersagen und Marktentwicklungen ermöglichen. Unternehmen, die auf datenbasierte Entscheidungen setzen, steigern ihre Umsätze um 58 % schneller und erzielen ein jährliches Wachstum von über 30 %.
Kernpunkte:
- Datenquellen: Zulassungsstatistiken, Händlerdaten, Online-Anzeigen, Bilder, Suchtrends.
- Verfahren: Zeitreihenanalysen, Regressionsmodelle, Machine Learning.
- Herausforderungen: Datenbereinigung, Konsistenz zwischen Quellen, regionale Unterschiede.
- Nutzen: Verbesserte Preisgestaltung, präzisere Prognosen, effizientere Planung.
Big Data liefert nicht nur genauere Vorhersagen, sondern auch entscheidende Vorteile für Unternehmen, die ihre Prozesse optimieren und Risiken minimieren wollen.
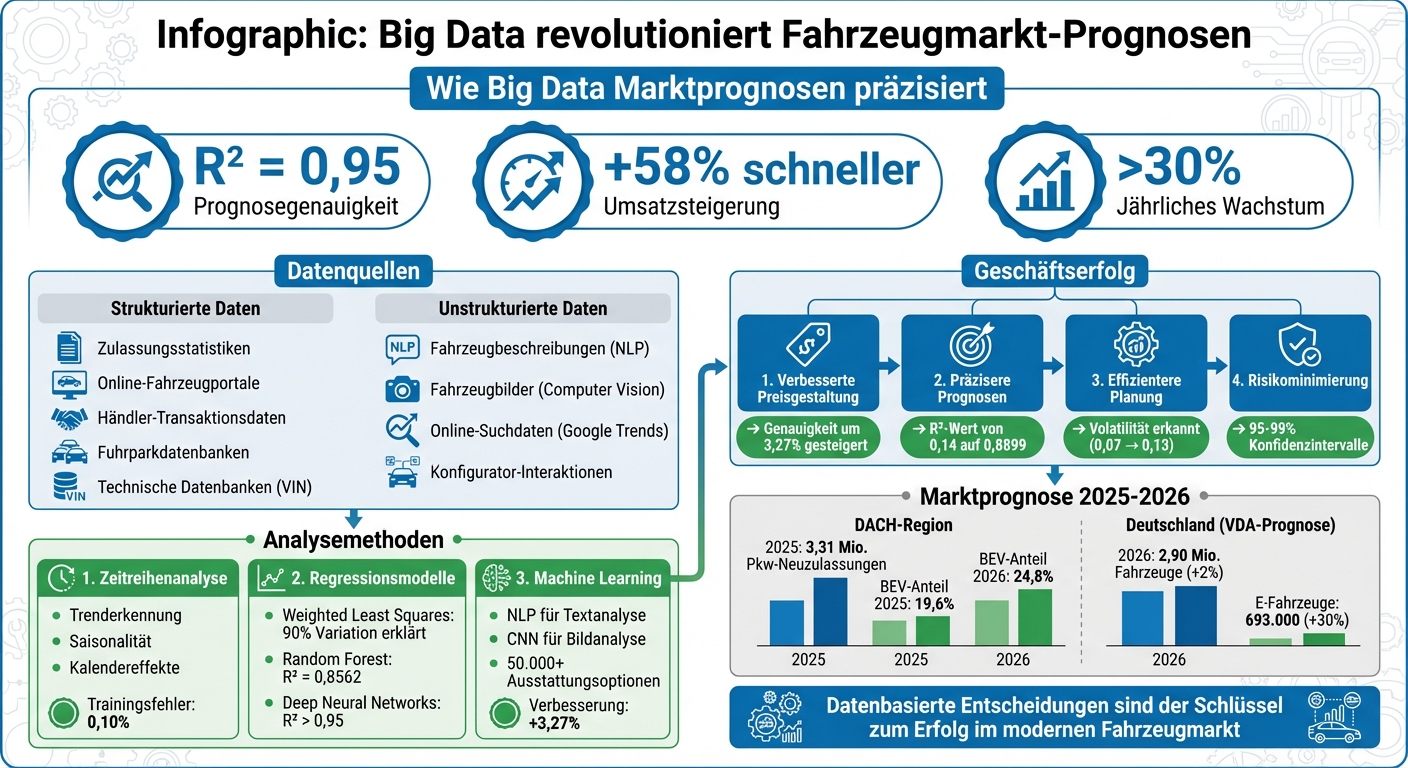
Big Data im Fahrzeugmarkt: Datenquellen, Methoden und Geschäftserfolg
Datenquellen für Fahrzeugmarktprognosen
Marktprognosen stehen und fallen mit der Qualität der zugrunde liegenden Datenquellen. Im Fahrzeugmarkt gibt es zwei wesentliche Kategorien: strukturierte Daten aus offiziellen Systemen und unstrukturierte Daten, etwa aus Online-Inhalten. Beide liefern unterschiedliche, aber sich ergänzende Perspektiven auf Marktentwicklungen.
Strukturierte Datenquellen
Strukturierte Daten sind das Rückgrat jeder Marktprognose. Sie bieten präzise und zuverlässige Informationen:
- Zulassungsstatistiken: Diese geben Einblicke in Marktvolumen und Antriebstrends. Beispielsweise prognostiziert Dataforce für 2025 etwa 3,31 Millionen Pkw-Neuzulassungen in der DACH-Region, mit einem Anstieg des BEV-Anteils von 19,6 % in 2025 auf 24,8 % in 2026.
- Online-Fahrzeugportale: Plattformen wie pkw.de ermöglichen die Echtzeitbeobachtung von Angebotspreisen. Im Februar 2026 lag der Durchschnittspreis für Mercedes-Benz Gebrauchtwagen bei 63.809 €, was einem Anstieg von 8,11 % im Vergleich zum Vorjahr entspricht.
- Händler-Transaktionsdaten: Diese sind noch präziser, da sie tatsächliche Verkaufspreise statt bloßer Angebotspreise abbilden.
- Fuhrparkdatenbanken: Sie liefern Details zu Ersatzzyklen und zukünftigen Gebrauchtwagenangeboten.
- Technische Datenbanken: Anhand von VIN-Nummern und Details wie Ausstattung und Motorisierung erlauben sie eine tiefgehende Bewertung einzelner Fahrzeuge.
Neben den quantitativen Daten tragen unstrukturierte Quellen dazu bei, qualitative Aspekte zu beleuchten.
Unstrukturierte Datenquellen
Unstrukturierte Daten erweitern die Analyse um wichtige Kontextinformationen.
- Fahrzeugbeschreibungen in Online-Anzeigen: Diese enthalten oft Details zum Zustand oder zu Sondermerkmalen, die in technischen Spezifikationen fehlen. Mit NLP-Techniken wie word2vec oder fastText lassen sich solche Texte maschinenlesbar machen. Eine Studie von Maximilian Blanck zeigte, dass ein Feed-Forward Neural Network auf Basis von Fahrzeugbeschreibungen eine Genauigkeit von 45,78 % bei der Vorhersage von Preisabweichungen erreichte – nur 4,22 Prozentpunkte unter menschlicher Genauigkeit.
- Fahrzeugbilder: Mit Computer-Vision-Methoden wie EfficientNet können sichtbare Schäden und Sonderausstattungen analysiert werden.
- Online-Suchdaten: Plattformen wie Google Trends dienen als Frühindikatoren für Kaufinteresse. Doch Vorsicht: Laut Forschern der University of London können Suchtrends unterschiedliche Motivationen widerspiegeln und ohne ökonometrische Filter zu verzerrten Prognosen führen.
Kombination verschiedener Datenströme
Die Kombination mehrerer Datenquellen bietet ein umfassenderes Bild der Marktdynamik. Historische Verkaufsdaten zeigen vergangene Nachfragemuster, während Online-Verhaltensdaten – etwa aus Konfigurator-Interaktionen – Hinweise auf zukünftige Entwicklungen geben.
Ein Beispiel: Im November 2025 veröffentlichten Tom Nahrendorf und Stefan Minner von der Technischen Universität München eine Studie, die Verkaufsdaten mit Konfigurator-Interaktionen kombinierte. Durch Mixed-Integer Linear Programming (MILP) konnten konsistente Prognosen über alle Hierarchieebenen hinweg erstellt werden. Die Integration von Online-Verhaltensdaten verbesserte die Genauigkeit auf Produkt- und Marktebene erheblich.
"Online behavioral data considerably improving accuracy at disaggregated levels." – Tom Nahrendorf, Researcher, Technical University of Munich
Die größte Herausforderung bleibt, Konsistenz und Zuverlässigkeit zwischen den verschiedenen Datenquellen sicherzustellen. Methoden wie Integer-Coherent Reconciliation helfen, Prognosen mathematisch korrekt zu aggregieren – ein entscheidender Faktor, besonders für Premium-Hersteller mit komplexer Modellvielfalt.
Datenaufbereitung für Marktprognosen
Daten aus Quellen wie Fahrzeugportalen, Zulassungsstellen oder Händlersystemen sind oft unvollständig, inkonsistent oder enthalten Rauschen. Solche Schwächen können Prognosemodelle erheblich beeinträchtigen. Selbst automatisierte Algorithmen liefern nur dann verlässliche Ergebnisse, wenn die zugrunde liegenden Daten sorgfältig aufbereitet sind. Die Qualität der Daten ist dabei entscheidend: Sie bestimmt, ob ein Modell Markttrends akkurat abbildet oder systematische Fehler verursacht. Daher ist eine gründliche Datenbereinigung unverzichtbar, um präzise Vorhersagen zu ermöglichen.
Methoden zur Datenbereinigung
Der erste Schritt in der Datenbereinigung ist die Standardisierung. Unterschiedliche Schreibweisen wie „Automatik“, „Auto“ oder „A“ werden mithilfe regelbasierter Zuordnungen vereinheitlicht. Motorspezifikationen wie „2.0 TDI 150 PS“ werden mit Regular Expressions in numerische Werte für Hubraum und Leistung umgewandelt (r = 0,61).
Fehlende Werte erfordern einen gezielten Ansatz: Wenn z. B. der Unfallstatus fehlt, wird „Keine Angabe“ ergänzt. Bei unklaren Angaben zum Fahrzeugbrief wird „Nein“ angenommen. Um Ausreißer zu identifizieren – etwa bei extremen Preis- oder Kilometerangaben – kommt die Interquartilsmethode (IQR) zum Einsatz. Für Merkmale mit vielen Kategorien, wie Fahrzeugmarken, wird Target Encoding genutzt. Dabei erhält jede Marke einen Wert, der auf ihrem durchschnittlichen Marktpreis basiert, um markenspezifische Trends besser abzubilden.
Imran Fayyaz von der Bradley University hebt hervor:
"Thoughtful, domain-informed preprocessing can improve R2 scores by over 10× in some cases."
Ein Beispiel zeigt, wie strukturierte Aufbereitung den R²-Score eines Stacking Regressors von 0,14 auf 0,8899 verbesserte. Auch die Korrelation zwischen Kilometerstand und Preis wurde durch Normalisierung verstärkt – von r = -0,31 auf r = -0,73.
Herausforderungen bei Fahrzeugdaten
Fahrzeugdaten bringen spezifische Probleme mit sich. Regionale Preisunterschiede erfordern eine geografische Normalisierung. Eine der größten Hürden ist jedoch die enorme Vielfalt an Ausstattungsoptionen. Moderne Fahrzeuge bieten über 50.000 mögliche Kombinationen. Eine Analyse von 92.239 Verkaufsdatensätzen zeigte, dass die Berücksichtigung detaillierter Ausstattungsmerkmale wie Alufelgen oder Einparkhilfen die Prognosegenauigkeit (Mean Absolute Error) um 3,27 % steigern kann.
Sicherstellung von Datenqualität und Konsistenz
Neben der Bereinigung ist es entscheidend, die Datenqualität kontinuierlich zu prüfen. Back-Testing mit historischen Daten bewertet die Vorhersagegenauigkeit der Modelle. Cross-Validation, bei der Daten in Trainings- und Testsets aufgeteilt werden, hilft, Überanpassungen zu erkennen. Besonders wichtig ist die Konsistenz zwischen unterschiedlichen Datenquellen. Während in Deutschland die Schwacke-Liste als Standard gilt, müssen internationale Daten an vergleichbare Bewertungsmaßstäbe angepasst werden.
Ein Beispiel liefert das Fraunhofer-Institut für Techno- und Wirtschaftsmathematik (ITWM): Es entwickelte ein Modell für Leasingverträge, das durch die Integration verschiedener Datenquellen und Anomalieerkennung geringere Abweichungen von tatsächlichen Restwerten erreichte als Branchenbenchmarks.
Christoph Gleue von der Leibniz Universität Hannover warnt:
"Either a systematic overestimation or underestimation of future residual values can incur large potential losses in resale value or, respectively, competitive disadvantages."
Für Unternehmen wie die CUBEE Sachverständigen AG, die digitale KFZ-Gutachten erstellen, ist Datenqualität besonders wichtig. Präzise Gutachten setzen voraus, dass Fahrzeugdaten – von technischen Spezifikationen bis hin zu Schadensdetails – konsistent und korrekt aufbereitet werden.
Big Data-Analysemethoden für Marktprognosen
Nach der Datenbereinigung folgt der entscheidende Schritt: die Analyse. Hier kommen drei Hauptmethoden ins Spiel: Zeitreihenanalyse, um langfristige Trends zu identifizieren, Regressionsmodelle, um Preise zu berechnen, und Machine Learning, um komplexe Muster zu erkennen. Jede Methode bringt ihre eigenen Stärken mit, und ihre Kombination führt zu besonders präzisen Ergebnissen.
Zeitreihenanalyse zur Trenderkennung
Die Zeitreihenanalyse teilt historische Fahrzeugdaten in vier Hauptbestandteile auf: Trend (langfristige Entwicklung), Saisonalität (wiederkehrende Muster), Kalendereffekte (z. B. Feiertage) und Rauschen (zufällige Schwankungen). Moderne Ansätze berücksichtigen dabei auch externe Faktoren wie das Bruttoinlandsprodukt, die Arbeitslosenquote oder Zinssätze.
Bernhard Brühl vom Fraunhofer-Institut betonte, dass quartalsweise Daten eine gute Balance zwischen Datenmenge und Stabilität bieten und genauer sind als Jahres- oder Monatsdaten. Zudem schneiden nicht-lineare Modelle wie Support Vector Machines (SVM) besser ab als klassische Multiple Linear Regression. So erreichen sie Trainingsfehlerraten von nur 0,10 % bei Jahresmodellen.
Auch der Website-Traffic von Fahrzeugkonfiguratoren wird zunehmend analysiert, um kurzfristige Nachfrage besser vorherzusagen. Probabilistische Prognosen, wie sie mit Quantilregression erstellt werden, ergänzen Punktvorhersagen durch Unsicherheitsbereiche, z. B. 95-%-Prognoseintervalle. Das verbessert das Risikomanagement erheblich. Diese Ergebnisse bilden die Grundlage für die nachfolgende Preisanalyse mit Regressionsmodellen.
Regressionsmodelle zur Preisschätzung
Regressionsmodelle nutzen strukturierte Daten, um Fahrzeugpreise vorherzusagen. Die Weighted Least Squares (WLS)-Methode erklärt beispielsweise 90 % der Preisunterschiede bei Gebrauchtwagen. Noch leistungsfähiger sind Ensemble-Methoden wie Gradient Boosted Trees (GBT), die in Big-Data-Umgebungen die höchste Genauigkeit bei RMSE und R²-Werten liefern. Allerdings benötigen sie mehr Rechenzeit als Random-Forest-Modelle.
Zu den wichtigsten Preisfaktoren zählen Alter, Marke und Motorleistung. Eine Analyse von 250.000 Leasingverträgen zeigte, dass fahrzeugspezifische Daten oft aussagekräftiger sind als makroökonomische Indikatoren. Christoph Gleue von der Leibniz Universität Hannover erklärte dazu:
"Vehicle-specific data or, in more general terms, the exclusive data of corporations... is often only available internally."
Deep-Learning-Modelle, die auf deutschen und rumänischen Märkten getestet wurden, erzielten R²-Werte von über 0,95. Bei bekannten Marken wie BMW, Volkswagen und Tesla erreichten Random-Forest-Modelle einen R²-Wert von 0,8562.
| Modelltyp | Hauptvorteil | Leistungsbeispiel |
|---|---|---|
| Weighted Least Squares | Erklärt hohe Preisvarianzen | 90 % Variation erklärt |
| Random Forest | Guter Kompromiss zwischen Tempo und Genauigkeit | R² = 0,8562 |
| Gradient Boosted Trees | Höchste Genauigkeit bei großen Datenmengen | Beste RMSE/R²-Werte |
| Deep Neural Networks | Erkennt komplexe Muster | R² > 0,95 |
Während Regressionsmodelle Preiszusammenhänge quantifizieren, geht Machine Learning noch einen Schritt weiter und erkennt komplexe, nicht-lineare Muster.
Machine Learning zur Mustererkennung
Machine Learning eröffnet Möglichkeiten, die klassische Modelle nicht bieten. Mit Natural Language Processing lassen sich aus unstrukturierten Daten, wie Motorspezifikationen („2.0 TDI 150 PS“), numerische Werte extrahieren. Automatisierte Verfahren analysieren zudem mehr als 50.000 Ausstattungsoptionen – von Alufelgen bis zu Einparkhilfen – und bewerten deren Einfluss auf den Wiederverkaufswert.
Convolutional Neural Networks (CNN) analysieren Fahrzeugbilder, um visuelle Merkmale zu identifizieren, die den Preis beeinflussen. Methoden wie Stacking Regressors, CatBoost und XGBoost kombinieren mehrere Modelle, um komplexe Zusammenhänge zwischen Unfallhistorie, Markenwert und Kilometerstand zu entschlüsseln. Durch umfassendes Feature Engineering konnte der R²-Wert eines Stacking Regressors von 0,14 auf 0,8899 gesteigert werden.
Target Encoding hilft Machine-Learning-Modellen dabei, nicht-lineare Wechselwirkungen zwischen Marken- und Ausstattungsmerkmalen zu erfassen. Solche Details bleiben in einfachen Regressionsmodellen oft unsichtbar. Unternehmen wie die CUBEE Sachverständigen AG, die digitale KFZ-Gutachten erstellen, profitieren von diesen Ansätzen. Sie ermöglichen präzisere Wertermittlungen, insbesondere bei komplexen Fällen wie Oldtimern oder Schadensbewertungen, wo Ausstattungsdetails entscheidend sind.
Aufbau und Test von Prognosemodellen
Sobald die Analysemethoden festgelegt sind, beginnt die eigentliche Arbeit: Modelle auswählen, trainieren und kontinuierlich anpassen. Dieser Schritt entscheidet, ob die Prognosen präzise genug sind, um fundierte Entscheidungen zu ermöglichen.
Modellauswahl und Training
Die Wahl des Modells hängt stark von der Datenmenge und den angestrebten Genauigkeitszielen ab. Gute Modelle berücksichtigen Faktoren wie Trends, Saisonalität, Kalendereffekte und Rauschen. Für die Erkennung von Trends bieten nicht-lineare Algorithmen wie Support Vector Machines (SVM) oder LightGBM oft bessere Ergebnisse als die klassische lineare Regression.
Beim Training kommen drei Hauptansätze ins Spiel:
- Direct-Methode: Separate Modelle für jeden Prognosezeitraum, um Fehlerakkumulation zu vermeiden.
- Recursive-Methode: Ein Modell, das frühere Vorhersagen als Eingabe für die nächsten nutzt.
- Hybrid-Methode: Eine Kombination aus beiden Strategien.
Ein Beispiel aus der Praxis: Im November 2025 arbeiteten die Forscher Tom Nahrendorf und Stefan Minner mit einem deutschen Premium-Automobilhersteller zusammen. Sie setzten ein Ensemble aus LightGBM-Modellen ein, kombiniert mit Mixed-Integer Linear Programming (MILP). Ihre Shapley-Analyse zeigte, dass mittelfristige Nachfrage besonders von Online-Engagement und Wettbewerbsindikatoren beeinflusst wird.
Um externe Faktoren wie BIP oder Zinssätze präzise zu integrieren, werden Daten oft mittels Z-Transformation normalisiert. Diese baut auf vorherigen Bereinigungstechniken auf und erleichtert die Einbindung wirtschaftlicher Einflüsse. Eine Korrelationsanalyse hilft dabei, die optimalen Zeitverzögerungen zu bestimmen. Bei komplexen Produktlinien sorgt MILP dafür, dass Prognosen auf allen Ebenen – von der Gesamtmarktebene bis hin zu einzelnen Varianten – konsistent bleiben.
Nach dem Training muss die Modellgenauigkeit mit klar definierten Metriken überprüft werden.
Leistungsmessung der Modelle
Die Genauigkeit von Prognosemodellen wird vor allem durch drei Metriken bewertet: Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE) und Root-Mean-Square Error (RMSE). In volatilen Märkten kann zusätzlich Quantilregression eingesetzt werden, um Unsicherheitsbereiche wie 95-%-Prognoseintervalle abzubilden.
Die Zuverlässigkeit wird durch K-Fold-Kreuzvalidierung oder Rolling-Origin-Validierung sichergestellt. Diese Methoden verhindern, dass Trainingsdaten in die Testphase einfließen. In einer Untersuchung zu Gebrauchtwagenpreisen erreichte ein Random-Forest-Modell beispielsweise einen R²-Wert von 0,8562. SVM-Modelle für deutsche Pkw-Neuzulassungen zeigten Trainingsfehler von nur 0,10 %, während die Testfehler auf 1,47 % stiegen – ein Hinweis auf mögliches Overfitting. Quartalsweise Daten lieferten dabei stabilere Ergebnisse: Der mittlere Testfehler lag bei 4,86 %, während monatliche Daten 11,23 % erreichten.
Für praktische Anwendungen müssen Prognosen hierarchisch kohärent sein – d. h., Vorhersagen für einzelne Modellvarianten sollten sich zur Gesamtmarke aufsummieren. Mithilfe des Kwiatkowski-Phillips-Schmidt-Shin (KPSS)-Tests kann geprüft werden, ob Fehlermuster über die Zeit konstant bleiben, was für die Stabilität der Modelle entscheidend ist.
Da sich Marktbedingungen ständig ändern, ist eine regelmäßige Anpassung der Modelle unerlässlich.
Modelle kontinuierlich verbessern
Regelmäßige Updates sind entscheidend, um Modelle aktuell und effektiv zu halten. Ensemble-Methoden, die Direct-, Recursive- und Hybrid-Strategien kombinieren, können Verzerrungen minimieren und die Stabilität erhöhen. Eine Analyse von 92.239 Verkaufsaufzeichnungen aus dem März 2025 zeigte, dass die Integration von 50.000 granularen Ausstattungsoptionen – automatisiert verarbeitet – die Vorhersagegenauigkeit um 3,27 % verbesserte.
Feature Engineering ist dabei ein zentraler Faktor. Beispielsweise konnte durch kategoriale Kodierung und die Entfernung von Ausreißern der R²-Wert eines Stacking Regressors von 0,14 auf 0,8899 gesteigert werden. Explainable AI (XAI)-Tools helfen dabei, die wichtigsten Einflussfaktoren – etwa den Produktlebenszyklus oder die Online-Nachfrage – zu identifizieren. Mit Werkzeugen wie AutoGluon lassen sich mehrere Algorithmen automatisiert kombinieren, was besonders für kleinere Unternehmen hilfreich ist.
Regelmäßige Updates mit über 30 wirtschaftlichen, demografischen und branchenspezifischen Indikatoren verbessern die Leistung in unsicheren Zeiten. Interessanterweise stiegen die Variationskoeffizienten für deutsche Pkw-Neuzulassungen von 0,07 (2016–2019) auf 0,13 (2020–2023), was auf zunehmende Marktschwankungen hinweist. Solche adaptiven Modelle sind besonders nützlich für präzise digitale KFZ-Gutachten, wie sie beispielsweise von der CUBEE Sachverständigen AG angeboten werden. Diese Ansätze helfen Unternehmen, präzise Wertermittlungen für Schadensbewertungen oder Oldtimer-Gutachten auf Basis aktueller Marktdaten durchzuführen.
Prognosen für Geschäftsentscheidungen nutzen
Modelle entfalten ihren Nutzen erst dann, wenn ihre Ergebnisse in konkrete Entscheidungen umgesetzt werden. Hier sind einige Ansätze, wie Prognosen in der Praxis angewandt werden können.
Datenvisualisierung und Berichte
Damit Prognosen für Entscheidungsträger nützlich sind, müssen sie klar und verständlich präsentiert werden. Probabilistische Vorhersagen mit Konfidenzintervallen sind hier hilfreich, da sie eine Bandbreite möglicher Ergebnisse aufzeigen. Beispielsweise nutzen Unternehmen für die monatliche Fahrzeugallokation häufig 50- bis 67-%-Prognoseintervalle. Für langfristige Kapazitätsplanung und Risikobewertungen kommen hingegen 95- bis 99-%-Intervalle zum Einsatz.
Explainable AI (XAI) bringt Transparenz in Prognosen. Mithilfe der Shapley-Analyse können Entscheidungsträger nachvollziehen, welche Faktoren – wie der Traffic auf Online-Konfiguratoren oder Produktlebenszyklen – die Vorhersagen beeinflussen. Tom Nahrendorf von der Technischen Universität München hebt hervor:
„Der Wert verbesserter Prognosen liegt nicht nur in höherer Vorhersagegenauigkeit, sondern auch in effektiverer Entscheidungsfindung durch reduzierte Betriebskosten, effizientere Ressourcenallokation und besseres Risikomanagement."
Für die operative Planung sind zudem ganzzahlige Prognosen entscheidend. Dezimalrundungen können hier hierarchische Konsistenz gefährden, und selbst ein Fehler von ±1 Einheit kann bei kleinen Stückzahlen gravierende Auswirkungen auf Lagerbestände und Produktionskapazitäten haben.
Planung für verschiedene Marktszenarien
Prognosen helfen Unternehmen, sich auf unterschiedliche Marktsituationen vorzubereiten. Ein Beispiel: Der deutsche Automobilmarkt hat in den letzten Jahren eine deutliche Zunahme der Volatilität erlebt. Der Variationskoeffizient für Pkw-Neuzulassungen stieg von 0,07 (2016–2019) auf 0,13 (2020–2023). In diesen unsicheren Zeiten ermöglichen multivariate Modelle Simulationen, um die Auswirkungen von Faktoren wie BIP-Änderungen oder handelspolitischen Entscheidungen zu analysieren.
Der Verband der Automobilindustrie (VDA) rechnet bis 2026 mit einem Anstieg der Neuzulassungen um 2 % auf 2,90 Millionen Fahrzeuge. Für Elektrofahrzeuge wird ein Wachstum um 30 % auf etwa 693.000 Einheiten prognostiziert. Solche Entwicklungen erfordern flexible Planungsansätze, die verschiedene Szenarien berücksichtigen.
Quantilregression ist ein weiteres Werkzeug, das die Modellierung von Nachfrageextremen erleichtert. So können Unternehmen nicht nur mit Durchschnittswerten planen, sondern auch Puffer für seltene, aber einflussreiche Marktschwankungen einbauen. Für Unternehmen wie die CUBEE Sachverständigen AG bedeutet dies, dass Fahrzeugbewertungen auf aktuellen Daten basieren, die optimistische wie auch pessimistische Szenarien abbilden.
Neben strategischen Überlegungen ist es ebenso wichtig, Prognosen in den täglichen Betrieb zu integrieren.
Prognosen im Tagesgeschäft anwenden
Bereiche wie Preisgestaltung, Bestandsmanagement und Kundenkommunikation profitieren direkt von präzisen Marktprognosen. Studien zeigen, dass die Einbindung von bis zu 50.000 detaillierten Ausstattungsoptionen – beispielsweise Parkhilfen oder Felgentypen – die Vorhersagegenauigkeit für Wiederverkaufswerte um 3,27 % steigern kann.
Methoden wie Dezil-Binning und Demand Sensing helfen, aktuelle Kundenpräferenzen zu erkennen und in Preisstrategien umzusetzen. Beim Dezil-Binning werden prognostizierte Fahrzeugwerte in Kategorien unterteilt, sodass Vertriebsteams schnell Prioritäten setzen können. Demand Sensing nutzt Online-Daten, wie den Traffic auf Fahrzeugkonfiguratoren, um Kundenwünsche zu erfassen, bevor sie sich in Verkäufen widerspiegeln.
Deutsche Premium-Hersteller bieten mehr als fünfmal so viele werkseitige Optionen wie japanische Volumenhersteller an. Diese Vielfalt erhöht die Komplexität der Prognosen. Automatisierte Ensemble-Methoden wie AutoGluon kombinieren verschiedene Algorithmen und machen solche Analysen auch für kleine und mittlere Unternehmen zugänglicher. Gleichzeitig ist es wichtig, externe Signale – etwa wirtschaftliche Trends – kontinuierlich zu überwachen und operative Anpassungen vorzunehmen, sei es in der Kapazitätsplanung, Lagerverwaltung oder im Marketing.
| Planungsebene | Hauptanwendung | Wichtigste Visualisierungsmetrik |
|---|---|---|
| Strategisch (Aggregiert) | Langfristige Kapazitäts- und Markenplanung | Trendlinien mit 95-%-Konfidenzintervallen |
| Operativ (Markt-Produkt) | Monatliche Fahrzeugzuteilung & Bestand | Ganzzahlige Punktprognosen + 67-%-Intervalle |
| Risikomanagement | Supply-Chain-Puffer & Finanzabsicherung | Extreme Quantile (99. Perzentil) |
| Marketing | Aktionsplanung & Verkaufsziele | Shapley-Werte (Treiber-Wichtigkeit) |
Fazit
Die vorgestellten Big-Data-Methoden bieten nicht nur genauere Marktprognosen, sondern bilden auch die Grundlage für fundierte Geschäftsstrategien. Die Integration von detaillierten Fahrzeugdaten – wie etwa spezifischen Ausstattungsmerkmalen (z. B. Parkhilfen oder Felgentypen) – steigert die Vorhersagegenauigkeit für Wiederverkaufswerte um 3,27 %. Auch wenn dieser Anstieg auf den ersten Blick gering erscheinen mag, hat er erhebliche Auswirkungen auf die Rentabilität von Leasingunternehmen und Händlern. Schließlich hängen präzise Restwertprognosen direkt mit der Wirtschaftlichkeit zusammen.
Machine-Learning-Methoden übertreffen traditionelle statistische Ansätze bei Weitem. Besonders in einem dynamischen Marktumfeld wie dem deutschen Automobilmarkt, wo der Variationskoeffizient von 0,07 (2016–2019) auf 0,13 (2020–2023) gestiegen ist, zeigen multivariate Modelle ihre Stärke. Automatisierte Tools wie AutoGluon ermöglichen es sogar kleinen und mittleren Unternehmen, von diesen Technologien zu profitieren, ohne eine eigene Datenwissenschaftsabteilung zu benötigen. Dabei haben fahrzeugspezifische Daten oft eine höhere Aussagekraft als allgemeine makroökonomische Faktoren.
Die Zukunft wird von diesen technologischen Fortschritten geprägt sein. Bis 2030 wird in Europa mit etwa 90 Millionen vernetzten Fahrzeugen gerechnet. Unternehmen, die diese Datenströme effektiv nutzen, sichern sich einen klaren Wettbewerbsvorteil.
Datenbasierte Entscheidungen sind längst keine Option mehr, sondern eine Notwendigkeit. Die vorgestellten Ansätze – von Zeitreihenanalysen über Regressionsmodelle bis hin zu Machine-Learning-Technologien – ermöglichen professionelle Fahrzeugbewertungen, eine effizientere Ressourcenplanung und besseres Risikomanagement. Unternehmen, die jetzt in Big-Data-Analysen investieren, legen den Grundstein für langfristigen Erfolg. Auch die CUBEE Sachverständigen AG setzt auf Big-Data-Methoden, um schnelle und professionelle KFZ-Gutachten zu erstellen und Unternehmen dabei zu unterstützen, verlässliche Marktprognosen zu treffen.
FAQs
Welche Datenquellen sind für Fahrzeugmarktprognosen besonders wichtig?
Für verlässliche Prognosen im Fahrzeugmarkt spielen drei Faktoren eine zentrale Rolle: aktuelle Marktdaten, Echtzeit-Daten und KI-gestützte Analysen.
- Marktdaten liefern wertvolle Einblicke in Preistrends, regionale Unterschiede und Nachfragemuster. Sie helfen dabei, den Markt besser zu verstehen und langfristige Entwicklungen abzuschätzen.
- Echtzeit-Daten ermöglichen es, Marktbewegungen sofort zu erfassen. Dadurch können Bewertungen schneller und genauer vorgenommen werden, was besonders in einem dynamischen Marktumfeld von Vorteil ist.
- Künstliche Intelligenz (KI) hebt die Analyse auf ein neues Level. Sie automatisiert komplexe Prozesse, reduziert menschliche Fehler und sorgt so für noch präzisere Vorhersagen.
Diese Kombination aus Daten und Technologie bildet die Grundlage für fundierte Entscheidungen und zuverlässige Marktprognosen in Deutschland.
Wie verhindert man, dass unsaubere Daten Prognosen verfälschen?
Um Fehler in Datensätzen zu vermeiden, ist es wichtig, Daten regelmäßig auf Fehler, Aktualität und Vollständigkeit zu prüfen. Dabei können sowohl manuelle Kontrollen als auch KI-gestützte Systeme eingesetzt werden, um fehlerhafte oder schlecht formatierte Daten zu identifizieren. Durch eine Kombination aus systematischen Überprüfungen, moderner Technologie und klar definierten Qualitätsrichtlinien lässt sich die Qualität der Prognosen zuverlässig sichern.
Welches Modell eignet sich am besten für Restwert- und Preisprognosen?
Das beste Modell für die Vorhersage von Restwerten und Preisen setzt auf datenbasierte Methoden, vor allem auf KI-gestützte Systeme. Diese Systeme greifen auf Echtzeit-Daten zurück, um Vorhersagen zu liefern, die präzise, schnell und nachvollziehbar sind. Dadurch entsteht eine verlässliche Basis, die fundierte Entscheidungen erleichtert.
Verwandte Blogbeiträge
- Digitale KFZ-Bewertung: Marktanalyse und Prognosen
- So liefert KI personalisierte Fahrzeugbewertungen
- Top 3 Technologien hinter Predictive Analytics in KFZ-Plattformen
- Marktdaten-Dashboards: Trends in der KFZ-Bewertung