
Cloudbasierte Plattformen für KFZ-Gutachten stehen vor einer zentralen Herausforderung: Latenz minimieren, um schnelle und zuverlässige Prozesse zu gewährleisten. Latenz, also die Verzögerung zwischen Datenübertragung und -verarbeitung, beeinflusst direkt die Effizienz von Schadensbewertungen. Besonders bei der Bildübertragung oder Echtzeit-Datenverarbeitung ist eine niedrige Latenz entscheidend.
Wichtige Erkenntnisse:
- Hauptursachen der Latenz: Netzwerklatenz (z. B. Entfernung zum Rechenzentrum) und Verarbeitungszeiten in der Cloud.
- Optimierungsmethoden: Edge Computing, Auto-Scaling und Caching reduzieren Verzögerungen erheblich.
- Technologische Ansätze: Microservices-Architekturen, optimierte APIs (z. B. gRPC, GraphQL) und Content Delivery Networks (CDNs) verbessern die Leistung.
- Monitoring und Vorhersagen: Echtzeit-Überwachung und Predictive Analytics helfen, Engpässe frühzeitig zu erkennen.
Lösungsvorschläge:
- Edge Computing: Datenverarbeitung näher am Einsatzort, z. B. durch lokale Gateways.
- Auto-Scaling: Dynamische Ressourcenanpassung bei Lastspitzen.
- API-Optimierung: Einsatz moderner Schnittstellen wie gRPC für Echtzeit-Anwendungen.
- Monitoring-Tools: Präzise Metriken zur Messung von Latenz und Vorhersage von Problemen.
Diese Ansätze sichern schnelle Bewertungsprozesse, auch bei datenintensiven Anwendungen wie hochauflösender Bildanalyse. Unternehmen, die diese Maßnahmen umsetzen, können die Nutzerzufriedenheit steigern und gleichzeitig Kosten reduzieren.
Latenzoptimierung für Cloud-basierte KFZ-Gutachten: 4 Schlüsselstrategien
Hauptursachen für Latenz in cloudbasierten Fahrzeugbewertungssystemen
Latenz entsteht durch eine Kombination verschiedener Faktoren. Diese lassen sich in zwei Hauptkategorien unterteilen: Verzögerungen im Netzwerk und Verarbeitungszeiten innerhalb der Infrastruktur. Beide beeinflussen direkt, wie schnell Schadensdaten zwischen dem Einsatzort und der Cloud übertragen werden können.
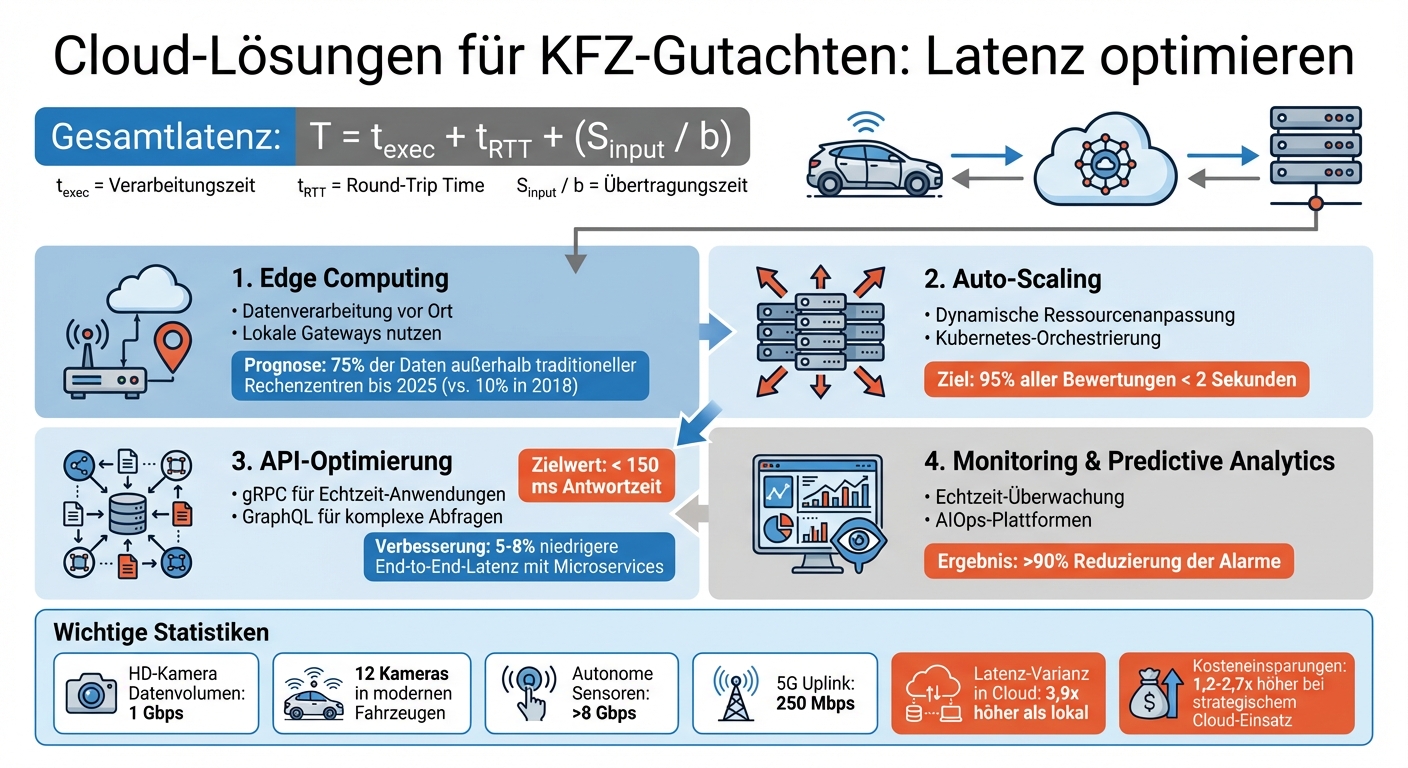
Die Gesamtlatenz wird durch die Formel T = t_exec + t_RTT + (S_input / b) beschrieben. Dabei steht t_exec für die Verarbeitungszeit, t_RTT für die Round-Trip Time und S_input / b für die Übertragungszeit, abhängig von der Datengröße (S_input) und der verfügbaren Bandbreite (b). Jeder dieser Faktoren kann zu Engpässen führen. Im Folgenden werden die wichtigsten Einflussfaktoren näher erläutert.
Wie Netzwerklatenz Fahrzeugbewertungen beeinflusst
Die Entfernung zwischen Einsatzort und Rechenzentrum spielt eine entscheidende Rolle für die Übertragungsgeschwindigkeit. Daten reisen durch Glasfaserkabel mit einer Geschwindigkeit von etwa 200.000 Kilometern pro Sekunde. Für eine Strecke von Berlin nach Frankfurt und zurück bedeutet das bereits eine Verzögerung von mehreren Millisekunden.
Besonders anspruchsvoll ist die Übertragung von Bilddaten. Eine einzelne HD-Kamera erzeugt ein Datenvolumen von etwa 1 Gigabit pro Sekunde. Moderne Fahrzeuge mit bis zu 12 Kameras erzeugen somit eine immense Datenlast, die Netzwerke stark beansprucht. Hinzu kommen autonome Sensorsysteme, die Datenmengen von über 8 Gbps generieren, während der Uplink bei 5G-Netzen oft nur 250 Mbps beträgt.
„Durch die Komprimierung der Bilddaten entsteht eine kleine Verzögerung bei der Übertragung, die sogenannte Latenz. In der Regel sind das fünf bis sechs Bilder pro Sekunde." – Prof. Benno Stabernack, Gruppenleiter, Fraunhofer HHI
Die Standard-Videokompression (H.264/H.265) reduziert zwar die Datenmenge, verursacht jedoch zusätzliche Verzögerungen. Diese Verfahren analysieren Unterschiede zwischen aufeinanderfolgenden Bildern, was zeitintensiv ist. Zusätzlich beeinträchtigen Jitter (Schwankungen in der Paketlaufzeit) und geringe Fehlerraten – auch wenn diese in 5G-Netzen unter 0,1 % liegen – die Übertragungskonsistenz.
Wie Cloud-Infrastruktur die Latenz beeinflusst
Auch die Cloud-Infrastruktur trägt erheblich zur Latenz bei. Studien der Universität Stuttgart zeigen, dass die Übertragungszeit stark vom geografischen Standort und den Netzwerkverbindungen der Backend-Server abhängt, während die Verarbeitungszeit hauptsächlich durch die eingesetzte Hardware bestimmt wird.
Ein weiterer Faktor sind Protokollkonvertierungen und Routing. Wenn Daten zwischen verschiedenen Netzwerkprotokollen – wie Ethernet und CAN-Gateways – umgewandelt werden, entstehen zusätzliche Verzögerungen. Veraltete Hardware, Legacy-Routing-Protokolle oder statische Konfigurationen in älteren Netzwerksegmenten können in Hybrid-Cloud-Umgebungen ebenfalls Engpässe verursachen.
Die geografische Nähe von Cloud-Subkonten und Backend-Systemen innerhalb desselben Hyperscaler-Rechenzentrums reduziert die Netzwerkdistanz erheblich. Das ist besonders entscheidend für datenintensive Anwendungen und Echtzeitanalysen, bei denen jede Millisekunde zählt.
Methoden zur Reduzierung der Latenz in Fahrzeugbewertungsplattformen
Die Latenz einer Plattform lässt sich durch den Einsatz von Edge Computing, Auto-Scaling und Caching deutlich verringern. Diese Ansätze ergänzen die zuvor genannten Ursachen und sorgen für eine konstant reaktionsschnelle Plattform.
Edge Computing: Datenverarbeitung direkt vor Ort
Edge Computing bringt Rechenleistung und Datenspeicherung näher an den Ort, an dem die Daten entstehen – beispielsweise zum mobilen Gerät des Gutachters oder einem lokalen Gateway. Statt große Datenmengen über weite Strecken zu senden, werden diese vor Ort gefiltert, optimiert und komprimiert. Nur die verarbeiteten Ergebnisse gelangen in die Cloud.
„Edge computing is about placing computer workloads (both hardware and software) as close as possible to the edge - to where the data is being created and where actions are occurring.“ – Glen Darling, IBM
Ein Beispiel: CUBEE unterstützt mobile Sachverständige, indem es lokale Recheneinheiten nutzt, um eine unterbrechungsfreie Bewertung zu ermöglichen. So können Schäden in Echtzeit vor Ort bewertet werden – selbst bei instabiler Internetverbindung. Diese lokale Verarbeitung sorgt dafür, dass Gutachter auch bei Netzwerkausfällen weiterarbeiten können. Gleichzeitig sinken die Übertragungskosten, da große Rohdateien nicht über Mobilfunknetze gesendet werden müssen. Prognosen zufolge werden bis 2025 etwa 75 % der Unternehmensdaten außerhalb traditioneller Rechenzentren verarbeitet – ein gewaltiger Anstieg im Vergleich zu nur 10 % im Jahr 2018.
Technologien wie containerisierte Microservices und Kubernetes-basierte Edge-Cluster ermöglichen es, Bewertungsdienste direkt vor Ort bereitzustellen. Diese Systeme unterstützen zudem automatische Überwachung und Skalierung. Für mobile Anwendungen kann eine Logik zur Live-Migration implementiert werden, die Backend-Dienste dynamisch zwischen verschiedenen Netzwerkzonen verschiebt.
Doch nicht nur Edge Computing ist entscheidend – auch die dynamische Anpassung von Ressourcen spielt eine zentrale Rolle.
Auto-Scaling: Flexible Ressourcen bei Bedarf
Auto-Scaling sorgt dafür, dass Ressourcen dynamisch an die aktuelle Auslastung angepasst werden. Wenn die Nachfrage steigt, werden automatisch neue Instanzen der Microservices bereitgestellt. Bei sinkender Last werden diese wieder entfernt.
Gerade für Fahrzeugbewertungsplattformen, die auf Echtzeitverarbeitung angewiesen sind, verhindert Auto-Scaling eine Überlastung der Ressourcen – und damit Verzögerungen. Statt sich auf Durchschnittswerte zu verlassen, können Plattformen probabilistische Latenzgarantien definieren, wie etwa die Verarbeitung von 95 % aller Bewertungen innerhalb von zwei Sekunden.
Die Kubernetes-Orchestrierung übernimmt die Überwachung der Auslastung und skaliert bei Bedarf automatisch. Bei Hardwareausfällen migriert das System Instanzen auf andere Maschinen im Cluster, was die Zuverlässigkeit erhöht. In Kombination mit Admission Control lässt sich zudem die maximale Antwortzeit vorhersagen, wenn mehrere Dienste dieselbe Hardware nutzen.
Neben der dynamischen Skalierung hilft auch Caching, die Latenz weiter zu verringern.
Caching und Content Delivery Networks (CDNs)
Caching und Content Delivery Networks (CDNs) reduzieren die Latenz, indem häufig benötigte Daten auf Servern gespeichert werden, die geografisch näher am Nutzer liegen. Für Fahrzeugbewertungsplattformen bedeutet das, dass Marktdaten, regionale Bewertungsvorlagen oder Referenzbilder lokal bereitgestellt werden, anstatt sie bei jeder Anfrage aus einem zentralen Rechenzentrum abzurufen.
Lokales Caching minimiert Verzögerungen, die durch große geografische Entfernungen entstehen können. Dies ist besonders effektiv bei datenintensiven Aufgaben wie der Videoanalyse von Fahrzeugschäden. Hier kann die Verarbeitung an lokale Edge-Server ausgelagert werden, die eine erste Analyse oder Texterkennung (OCR) durchführen und nur die Ergebnisse an die Cloud senden.
Eine hierarchische Struktur, bei der Edge-Geräte Daten zunächst an lokale Server übermitteln, die dann mit der zentralen Cloud synchronisiert werden, optimiert sowohl die Latenz als auch die Speicherkosten.
Durch die Kombination aus Edge Computing, Auto-Scaling und Caching entsteht eine leistungsstarke und latenzoptimierte Plattform für Fahrzeugbewertungen.
Verbesserung von APIs und Cloud-Architektur für bessere Performance
Die Architektur einer Cloud-Plattform hat direkten Einfluss auf die Geschwindigkeit und Zuverlässigkeit bei Fahrzeugbewertungen. Durch den Einsatz moderner Ansätze wie Microservices und optimierter APIs können Daten nahezu in Echtzeit ausgetauscht werden – ohne störende Verzögerungen, die den Arbeitsfluss beeinträchtigen. Eine solide Microservices-Architektur bildet die Basis, doch erst durch perfekt angepasste APIs wird die Echtzeit-Datenübertragung weiter beschleunigt.
Microservices-Architektur nutzen
Eine Microservices-Architektur zerlegt komplexe Bewertungsprozesse in kleine, unabhängige Dienste. Jede Funktion – sei es Bilderkennung, Schadensbewertung oder Berichterstellung – läuft isoliert in einem Container. Das bedeutet: Probleme in einem Bereich beeinträchtigen nicht die gesamte Plattform.
Durch den Einsatz containerisierter Microservices lässt sich die durchschnittliche End-to-End-Latenz um 5 % bis 8 % senken, verglichen mit traditionellen Systemen. Gleichzeitig ermöglicht diese Architektur die geografische Verteilung rechenintensiver Aufgaben, wie das Hochladen hochauflösender Schadensfotos, in Cloud-Regionen, die näher am Nutzer liegen.
"In the case of the presented microservice architecture, the mean end-to-end latency can be improved by 5-8 %." – Tobias Betz, Forscher
Ein weiterer Vorteil: Microservices nutzen Ressourcen wie CPU und Arbeitsspeicher effizienter als monolithische Systeme. Plattformen wie CUBEE profitieren davon, da sie auch bei hoher Auslastung reaktionsschnell bleiben. Jeder Dienst kann individuell skaliert werden, um den Anforderungen gerecht zu werden. Doch um Verzögerungen weiter zu minimieren, ist die Optimierung des Datenaustauschs über APIs entscheidend.
API-Performance für Echtzeit-Datenaustausch optimieren
APIs sind das Bindeglied zwischen Frontend und Backend und beeinflussen maßgeblich, wie schnell Daten abgerufen oder Berichte erstellt werden können. Die Wahl des richtigen API-Typs spielt dabei eine zentrale Rolle: Für Echtzeit-Anforderungen, wie etwa die Übertragung von Sensordaten oder die Betrugserkennung, ist gRPC dank seines geringen Overheads besser geeignet als REST. Bei komplexen Abfragen, bei denen nur bestimmte Datenfelder benötigt werden, hilft GraphQL, die übertragene Datenmenge zu reduzieren und die Antwortzeiten zu verkürzen.
API-Gateways wie AWS API Gateway oder Kong erleichtern die zentrale Verwaltung von Sicherheit, Versionierung und Monitoring. Allerdings können sie auch zu Latenzquellen werden, wenn sie nicht optimal konfiguriert sind. Ein Beispiel: Der Metrik-Wert statistics-approuter-total sollte regelmäßig überwacht werden, um Engpässe frühzeitig zu erkennen. Zudem empfiehlt sich die Nutzung des globalen Glasfasernetzes großer Anbieter. Durch „Cold Potato Routing“ bleibt der Datenverkehr so lange wie möglich im privaten Netzwerk des Anbieters, selbst wenn öffentliche IPs genutzt werden.
| API-Typ | Einsatzgebiet | Beispiel |
|---|---|---|
| gRPC | Hochperformante Echtzeitverarbeitung | Streaming von Transaktions- oder Sensordaten |
| REST API | Allgemeine Integrationen | Chatbots, die Fahrzeugdetails abrufen |
| GraphQL | Reduzierung von Datenüberladung | Analysetools mit verschachtelten Abfragen |
| Webhooks | Ereignisgesteuerte Workflows | Echtzeit-Benachrichtigungen bei Statusänderungen |
Tests zeigen, dass OData-Abfragen für Bewertungsdaten, wie etwa 10 Verkaufsaufträge, unter 150 ms Antwortzeit bleiben können, wenn die Architektur entsprechend ausgelegt ist. Diese Geschwindigkeit markiert die Schwelle, ab der Cloud-Offloading für Fahrzeugfunktionen praktikabel wird. Plattformen, die diese Grenze unterschreiten, gewährleisten auch bei hoher Nachfrage eine reibungslose und schnelle Nutzererfahrung.
Monitoring und Predictive Analytics für Latenzmanagement
Ohne ein effektives Monitoring bleibt Latenz oft unbemerkt – zumindest bis sie den Ablauf erheblich stört. Echtzeit-Monitoring und vorausschauende Analysen spielen eine Schlüsselrolle, um potenzielle Engpässe frühzeitig zu identifizieren, bevor sie den Bewertungsprozess beeinträchtigen. Insbesondere bei KFZ-Gutachten-Plattformen, die schnell und zuverlässig reagieren müssen, sind diese Ansätze unverzichtbar. Sie ergänzen bewährte Maßnahmen wie Auto-Scaling und Caching und schaffen eine solide Grundlage für ein umfassendes Latenzmanagement.
Tools zur Überwachung von Latenz-Metriken
Die Wahl der richtigen Metriken ist entscheidend, um von reaktivem Krisenmanagement zu einer proaktiven Optimierung überzugehen. Durchschnittswerte können verzerrt sein, da sie Ausreißer nicht angemessen berücksichtigen. Stattdessen sollte der Median (50. Perzentil) als Basiswert dienen, während das 99. Perzentil die „Worst-Case"-Erfahrungen abbildet, die etwa Gutachter im Außendienst betreffen.
In Cloud-nativen Umgebungen wie AWS EKS zeigt sich, dass die Latenz-Varianz bis zu 3,9-mal höher sein kann als in lokalen Docker-Setups. Dies deutet auf Ressourcenkonflikte in Multi-Tenant-Umgebungen hin. Um solche Abweichungen zu erkennen, ist es wichtig, die Varianz ($s_p$) der Latenz regelmäßig zu messen. Tools wie Dynatrace und Locust liefern präzise Benchmarks, während Visualisierungsplattformen wie Grafana in Kombination mit Zeitreihendatenbanken wie InfluxDB Echtzeit-Dashboards bereitstellen.
„You can't have a human looking at all of the email alerts from all the systems and expect them in real-time to be able to make good decisions. We use BigPanda AIOps to aggregate that information into a unified view so we can see how our systems are working holistically." – Keith Chernock, Director of Data Platforms, Dexcom
Um Verzögerungen gezielt aufzuspüren, sollten spezifische Metriken für einzelne Systemkomponenten regelmäßig überwacht werden. Für OData-Anfragen, die auf Bewertungsplattformen häufig sind, gilt eine Antwortzeit von unter 150 ms als akzeptabel. Im nächsten Abschnitt werfen wir einen Blick darauf, wie prädiktive Modelle dabei helfen können, zukünftige Engpässe frühzeitig zu erkennen.
Predictive Models zur Latenzverwaltung nutzen
Prädiktive Modelle gehen über die Echtzeitüberwachung hinaus, indem sie Muster analysieren und zukünftige Engpässe vorhersagen. Mithilfe vorausschauender Analysen lassen sich Traffic-Spitzen prognostizieren und gezielt Maßnahmen ergreifen. AIOps-Plattformen (Artificial Intelligence for IT Operations) setzen maschinelles Lernen ein, um Anomalien zu erkennen, Alarme zu bündeln und Ressourcen automatisch anzupassen. Ein Beispiel: Das Werbeunternehmen FreeWheel implementierte 2024 die AIOps-Plattform BigPanda und konnte die Anzahl der Alarme um über 90 % reduzieren, indem ähnliche Alerts automatisch zu übergeordneten Vorfällen zusammengefasst wurden.
Für präzise Vorhersagen sind hochwertige Zeitreihendaten unverzichtbar. Tools wie Apache JMeter simulieren Benutzeranfragen, während Datenbanken wie InfluxDB Metriken wie Antwortzeiten, Durchsatz und Jitter speichern, um Algorithmen zu trainieren. Plattformen wie IBM Watsonx können automatisch Modell-Pipelines erstellen, die speziell auf tabellarische Daten zugeschnitten sind – ideal für die Vorhersage von API-Latenz oder Traffic-Spitzen. Dennoch bleibt die geografische Optimierung, etwa durch die Platzierung von Cloud-Subaccounts in der Nähe der Backend-Systeme, die effektivste Maßnahme, um die Basis-Latenz zu minimieren, die von Modellen verwaltet werden muss.
Fazit: Eine Low-Latency-Cloud-Strategie für KFZ-Gutachten entwickeln
Dieses Fazit fasst die zentralen Punkte zusammen, um eine erfolgreiche Cloud-Strategie für KFZ-Gutachten-Plattformen umzusetzen.
Eine durchdachte Cloud-Strategie ist heute unverzichtbar für moderne Bewertungsplattformen. Die Kombination aus geografisch naher Cloud-Infrastruktur und modernen Technologien sorgt für schnelle und zuverlässige Prozesse. Unternehmen, die Cloud-Lösungen strategisch einsetzen, profitieren von 1,2- bis 2,7‑fach höheren Kosteneinsparungen im Vergleich zu solchen, die Cloud lediglich zur Effizienzsteigerung nutzen.
Ein hybrides Modell, das lokale und cloudbasierte Ressourcen kombiniert, hat sich als besonders effektiv erwiesen. Lokale, leichtgewichtige Modelle können als Fallback dienen, während aufwendige Aufgaben wie hochauflösende Bildanalysen oder KI-gestützte Schadenserkennung in der Cloud durchgeführt werden. Gerade bei Außendienst-Gutachten über 5G-Verbindungen zeigt sich, wie wichtig es ist, eine Balance zwischen Genauigkeit und effizienter Ressourcennutzung zu finden.
Wie bereits bei der Optimierung der API-Performance hervorgehoben, spielen klare SLOs (Service Level Objectives) eine entscheidende Rolle. Für zeitkritische Aufgaben sollte die Laufzeit nicht länger als 150 ms betragen. Gleichzeitig müssen Plattformen sicherstellen, dass Datenschutz und gesetzliche Vorgaben eingehalten werden. Fahrzeug- und Kundendaten müssen in den jeweiligen Jurisdiktionen verbleiben und den DSGVO‑Anforderungen entsprechen. Diese Anforderungen verdeutlichen, wie eng technische Präzision mit strategischer Planung verknüpft ist und wie beide gemeinsam den Markterfolg beeinflussen.
„Viewing cloud as a strategic enabler led to better outcomes against multiple business priorities, including 1.2x-2.7x greater cost savings than using cloud primarily to drive operational efficiency." – Accenture
Schnellere Bearbeitungszeiten, präzisere Ergebnisse und reibungslose mobile Anwendungen steigern die Zufriedenheit der Kunden. Durch kontinuierliches Monitoring und prädiktive Analysen lassen sich langfristige Wettbewerbsvorteile sichern.
FAQs
Wie hilft Edge Computing dabei, die Latenzzeiten bei KFZ-Gutachten zu minimieren?
Edge Computing ermöglicht es, Daten direkt dort zu verarbeiten, wo sie entstehen – vor Ort oder in nahegelegenen Edge-Knoten. Das bedeutet, dass große Datenmengen, wie etwa Bilder oder Sensordaten, nicht mehr über lange Strecken zu weit entfernten Cloud-Rechenzentren übertragen werden müssen. Das Ergebnis? Deutlich geringere Latenzzeiten und schnellere Verfügbarkeit der Ergebnisse, was besonders bei KFZ-Gutachten von Vorteil ist.
Ein gutes Beispiel hierfür ist der Einsatz bei der CUBEE Sachverständigen AG. Dort helfen digitalisierte Prozesse in Kombination mit Edge Computing, die Effizienz und Präzision der Begutachtungen zu optimieren. Die lokale Verarbeitung spart nicht nur wertvolle Zeit, sondern stellt auch sicher, dass die Datenintegrität erhalten bleibt – ein entscheidender Vorteil in einem datenintensiven Arbeitsumfeld.
Wie helfen Microservices dabei, die Latenz in cloudbasierten Plattformen zu reduzieren?
Microservices zerlegen eine Anwendung in kleine, eigenständige Dienste, die jeweils eine spezifische Funktion übernehmen. Diese Dienste kommunizieren über schlanke Netzwerk-APIs miteinander. Der Vorteil? Einzelne Dienste können unabhängig voneinander skaliert, aktualisiert und bereitgestellt werden. Das führt zu einer spürbaren Reduzierung der Gesamtlatenz – ein entscheidender Faktor für zeitkritische Anwendungen wie KFZ-Gutachten, bei denen Bild- und Sensordaten in Echtzeit verarbeitet werden müssen.
Ein weiterer Pluspunkt ist die Stabilität des Systems. Fällt ein Dienst aus, bleibt der Rest der Anwendung weiterhin funktionsfähig, da die Microservices voneinander isoliert sind. Zudem erlaubt diese Architektur eine gezielte Ressourcenzuweisung: Häufig genutzte Komponenten, wie etwa Bildanalyse-Engines, können mit zusätzlichen Ressourcen ausgestattet werden. Weniger genutzte Dienste hingegen sparen Ressourcen ein. Das Ergebnis? Ein effizienteres Kosten- und Ressourcenmanagement, insbesondere in Cloud-Umgebungen.
Damit Microservices ihr volles Potenzial entfalten, ist eine reibungslose Kommunikation zwischen den Diensten essenziell. Techniken wie Load-Balancing und klar definierte Schnittstellen helfen, die Netzwerklast zu minimieren und schnelle Verbindungen sicherzustellen. So verbessern Microservices nicht nur die Latenz, sondern erhöhen auch die Skalierbarkeit und Flexibilität von cloudbasierten Plattformen erheblich.
Warum sind Predictive Analytics entscheidend für die Optimierung der Latenzzeiten?
Predictive Analytics ermöglichen es, mögliche Latenzspitzen und Performance-Probleme frühzeitig zu identifizieren. Auf diese Weise können rechtzeitig Maßnahmen ergriffen werden, um Ausfallzeiten zu reduzieren und die Stabilität der Plattform zu sichern.
Das Ergebnis? Eine zuverlässigere Plattform, die gleichzeitig die Geschwindigkeit und Effizienz bei cloudbasierten KFZ-Gutachten verbessert. Mit Predictive Analytics bleibt Ihre Plattform flexibel und bestens gerüstet für kommende Herausforderungen.
Verwandte Blogbeiträge
- So liefert KI personalisierte Fahrzeugbewertungen
- Wie Cloud-Technologie die KFZ-Schadensbewertung verändert
- Wie digitale Prozesse die Qualität von KFZ-Gutachten verbessern
- API-Entwicklung für KFZ-Gutachten: Ein Leitfaden