
Elastische Ressourcenverteilung in der Cloud bedeutet, dass IT-Ressourcen wie CPU, RAM oder Speicherplatz automatisch an die aktuelle Nachfrage angepasst werden. Das System skaliert Ressourcen in Echtzeit nach oben oder unten, basierend auf der Arbeitslast. Das Ziel: Effizienz, Kosteneinsparungen und zuverlässige Leistung, selbst bei stark schwankenden Anforderungen.
Vorteile auf einen Blick:
- Automatische Skalierung: Ressourcen werden ohne manuelle Eingriffe bereitgestellt oder reduziert.
- Kosten sparen: Sie zahlen nur für tatsächlich genutzte Kapazitäten.
- Hohe Verfügbarkeit: Keine Ausfälle bei Lastspitzen, z. B. bei E-Commerce-Aktionen.
- Flexibilität: Horizontale (mehr Instanzen) und vertikale (stärkere Instanzen) Skalierung möglich.
Anwendung:
Ideal für Unternehmen mit variierenden Arbeitslasten, wie Streaming-Dienste oder Online-Shops, um Leistung und Kosten optimal zu managen.
Erfahren Sie, wie diese Technologie funktioniert, welche Tools sie unterstützt und warum sie für moderne Cloud-Systeme unverzichtbar ist.
Was ist elastische Ressourcenverteilung?
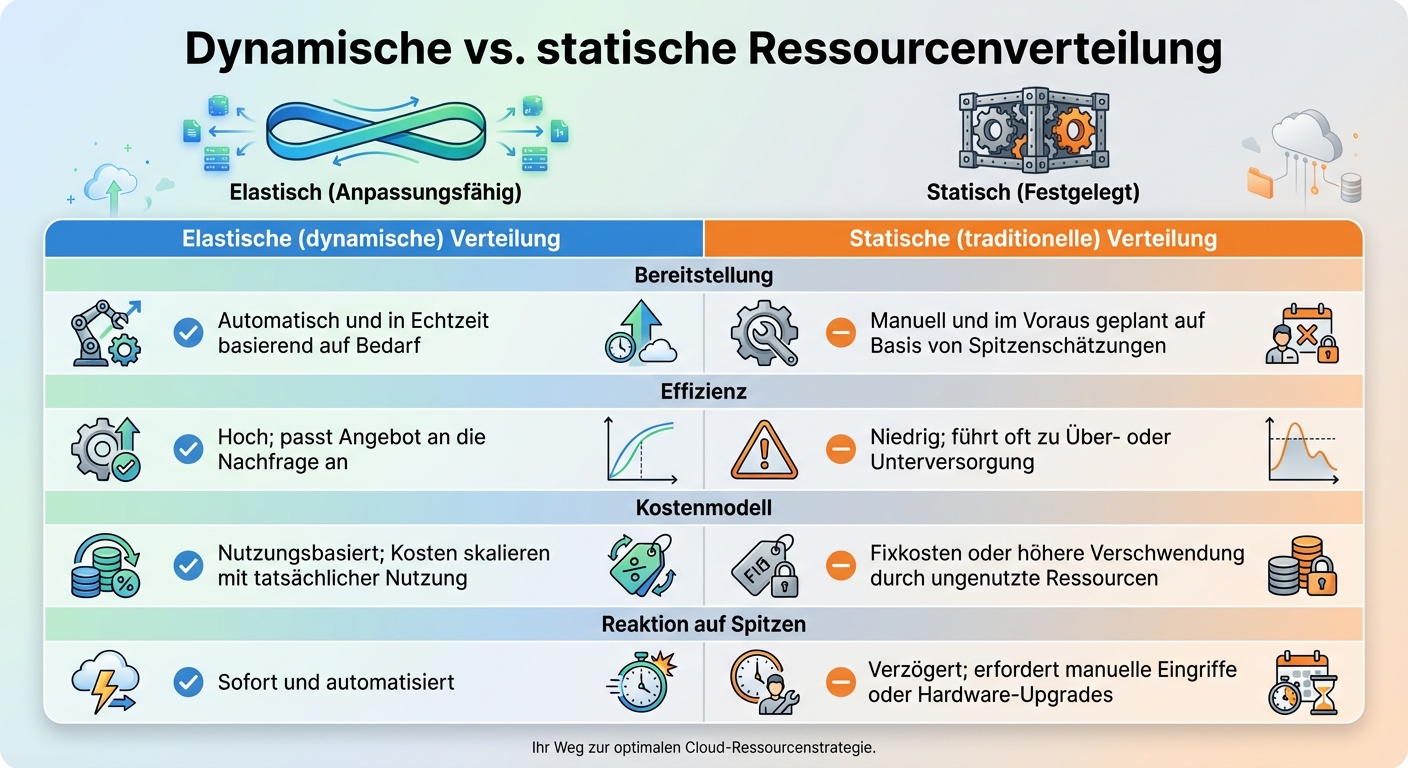
Elastische vs. statische Ressourcenverteilung: Vergleich der wichtigsten Merkmale
Elastische Ressourcenverteilung bedeutet, dass ein Cloud-System seine Rechenressourcen automatisch und in Echtzeit an schwankende Arbeitslasten anpasst. Das funktioniert entweder durch das Hinzufügen oder Entfernen von Instanzen (horizontal) oder durch das Anpassen der Leistungsfähigkeit einzelner Maschinen (vertikal), sobald bestimmte Schwellenwerte erreicht werden. Diese Anpassungen werden durch sogenannte „Autoscaler“ gesteuert, die kontinuierlich Leistungsmetriken überwachen und auf Veränderungen reagieren.
Ein anschauliches Beispiel: Während eines zweistündigen Flash-Sales in einem E-Commerce-Shop skaliert das System automatisch, um den erhöhten Traffic zu bewältigen, und reduziert die Kapazität wieder, sobald der Ansturm vorbei ist. Google Cloud beschreibt diesen Prozess mit einer treffenden Metapher:
„Elastizität ist wie ein Gummiband: Es kann sich dehnen, um mehr Arbeit zu bewältigen, und kehrt dann in seine ursprüngliche Form zurück, wenn die Arbeit erledigt ist".
Diese automatische Anpassung ist ein Schlüssel, um Kosten zu senken und die Leistung zu optimieren. Im nächsten Abschnitt wird der Unterschied zwischen dynamischer und statischer Ressourcenverteilung genauer betrachtet.
Dynamische vs. statische Ressourcenverteilung
Der Kernunterschied zwischen elastischer und statischer Ressourcenverteilung liegt in der Flexibilität und Effizienz. Eine statische Methode plant die Kapazität manuell anhand geschätzter Spitzenlasten. Das führt oft zu Überkapazitäten oder Engpässen. Im Gegensatz dazu passt die dynamische Methode die Ressourcen automatisch an die tatsächliche Nachfrage an, wodurch Verschwendung minimiert wird.
| Merkmal | Elastische (dynamische) Verteilung | Statische (traditionelle) Verteilung |
|---|---|---|
| Bereitstellung | Automatisch und in Echtzeit basierend auf Bedarf | Manuell und im Voraus geplant auf Basis von Spitzenschätzungen |
| Effizienz | Hoch; passt Angebot an die Nachfrage an | Niedrig; führt oft zu Über- oder Unterversorgung |
| Kostenmodell | Nutzungsbasiert; Kosten skalieren mit tatsächlicher Nutzung | Fixkosten oder höhere Verschwendung durch ungenutzte Ressourcen |
| Reaktion auf Spitzen | Sofort und automatisiert | Verzögert; erfordert manuelle Eingriffe oder Hardware-Upgrades |
Diese Gegenüberstellung zeigt, warum dynamische Ressourcenanpassung entscheidend ist, um Stabilität und Kosteneffizienz zu gewährleisten.
Warum Elastizität im Cloud Computing wichtig ist
Ohne Elastizität können zwei teure Probleme entstehen: Unterversorgung, die zu Systemabstürzen und einer schlechten Benutzererfahrung führt, und Überversorgung, bei der Unternehmen für ungenutzte Ressourcen zahlen. Für Branchen mit stark schwankenden Arbeitslasten – etwa Streaming-Plattformen bei neuen Releases oder Online-Shops während großer Verkaufsaktionen – ist diese Flexibilität unverzichtbar. Fortgeschrittene Systeme gehen noch einen Schritt weiter und nutzen prädiktive Skalierung. Dabei werden historische Daten analysiert, um Ressourcen schon vor einer erwarteten Lastspitze bereitzustellen.
Wie funktioniert elastische Ressourcenverteilung?
Elastische Ressourcenverteilung basiert auf Überwachungssystemen, automatisierten Regeln und Skalierungsmechanismen, die kontinuierlich Leistungskennzahlen erfassen. Sobald festgelegte Schwellenwerte erreicht werden, aktivieren Automatisierungs-Tools wie AWS Auto Scaling oder Google Cloud Autoscaler Skalierungsaktionen – ganz ohne menschliches Zutun.
Beim dynamischen Provisioning werden gezielt Ressourcen wie virtuelle Maschinen, Container oder Speichereinheiten hinzugefügt oder freigegeben. Load Balancer sorgen dafür, dass der Datenverkehr gleichmäßig verteilt wird, um Überlastungen zu vermeiden. Fortschrittliche Systeme nutzen prädiktive Skalierung, die auf Basis historischer Daten und KI zukünftige Traffic-Spitzen vorhersagt und Ressourcen im Voraus bereitstellt.
Im Folgenden werden die verschiedenen Skalierungsmechanismen, Ressourcentypen und die Rolle von Automatisierungs-Tools näher betrachtet.
Skalierungsmechanismen: Automatisch vs. manuell
Der Unterschied zwischen automatischer und manueller Skalierung liegt in der Art der Anpassung. Automatische Skalierung reagiert in Echtzeit auf vordefinierte Regeln und eliminiert die Notwendigkeit manueller Eingriffe. Sie ist das Herzstück der schnellen Elastizität. AWS hebt hervor, dass das manuelle Reagieren auf Alarme durch Kapazitätserhöhungen ein häufiges Anti-Pattern darstellt, das die Vorteile der Cloud-Elastizität untergräbt.
Manuelle Skalierung hingegen erfordert menschliches Eingreifen, etwa über Dashboards oder durch direkte Konfigurationsänderungen. Diese Methode eignet sich vor allem für geplante Ereignisse oder bei spezifischen Performance-Problemen. Welche Methode besser passt, hängt von der Vorhersehbarkeit der Arbeitslast ab: Automatisierung ist ideal bei unvorhersehbaren Schwankungen, während manuelle Anpassungen bei planbaren Szenarien sinnvoll sind.
Ressourcentypen bei elastischer Verteilung
Elastische Skalierung kann auf verschiedene Ressourcen angewendet werden, darunter CPU-Leistung, Arbeitsspeicher (RAM), Speicherkapazität und Netzwerkbandbreite. Diese Anpassungen erfolgen entweder horizontal durch das Hinzufügen weiterer Instanzen oder vertikal durch die Leistungssteigerung bestehender Maschinen. Moderne Ansätze setzen häufig auf Containerisierung mit Tools wie Docker und Kubernetes oder auf serverlose Architekturen, um noch flexiblere und präzisere Ressourcenanpassungen zu ermöglichen.
Der nächste Abschnitt beleuchtet, wie Automatisierungs- und Monitoring-Tools den Skalierungsprozess effizienter gestalten.
Rolle von Automatisierungs- und Monitoring-Tools
Monitoring-Systeme spielen eine zentrale Rolle, um sowohl Skalierungs- als auch Rückskalierungs-Ereignisse zu überwachen. So wird sichergestellt, dass Ressourcen korrekt freigegeben werden und unnötige Kosten vermieden bleiben. Dabei ist die Wahl der richtigen Metriken entscheidend: Bei Anwendungen, die Warteschlangen abarbeiten, sollte beispielsweise die „Queue Depth“ als Trigger dienen – nicht die CPU-Auslastung, selbst wenn diese bei 100 % liegt.
Tools wie Instance Templates oder Golden AMIs beschleunigen die Bereitstellung, indem sie exakte Kopien der aktuellen Umgebung erstellen. Durch den Einsatz solcher Standardlösungen können Unternehmen elastische Services effizient testen und implementieren.
Vorteile elastischer Ressourcenverteilung für variable Arbeitslasten
In diesem Abschnitt wird beleuchtet, wie Unternehmen von elastischen Ressourcen profitieren können, insbesondere bei variablen Arbeitslasten. Zu den hervorstechenden Vorteilen gehören nutzungsbasierte Abrechnung, zuverlässige Performance während Lastspitzen und eine präzise Anpassung der Ressourcen.
Kosteneinsparungen mit Pay-As-You-Go
Das Pay-As-You-Go-Modell verhindert unnötige Überkapazitäten. Unternehmen zahlen nur für die tatsächlich genutzten Ressourcen wie Rechenleistung, Speicher oder Bandbreite – häufig sogar auf die Sekunde genau . Dadurch entfallen teure Anfangsinvestitionen in Hardware oder eigene Rechenzentren. Dank automatisierter Elastizität werden Ressourcen freigegeben, sobald die Nachfrage sinkt, was den manuellen IT-Aufwand erheblich reduziert. Ein zusätzlicher Vorteil: Entwicklungs- und Testumgebungen können außerhalb der Geschäftszeiten automatisch abgeschaltet werden, was weitere Kosten spart.
Sicherstellung der Performance bei Lastspitzen
Elastische Systeme garantieren Stabilität und Zuverlässigkeit, auch wenn der Traffic plötzlich ansteigt. Zusätzliche Ressourcen werden automatisch bereitgestellt, um Verzögerungen oder Ausfälle zu vermeiden . Das AWS Well-Architected Framework beschreibt diesen Vorteil treffend:
„Configuring and testing workload elasticity will help save money, maintain performance benchmarks, and improves reliability as traffic changes."
Ein weiterer Fortschritt ist die prädiktive Autoskalierung. Mithilfe historischer Daten und maschinellen Lernens können Ressourcen bereits vor einer erwarteten Lastspitze aktiviert werden. Gleichzeitig verteilt ein Load Balancer den Datenverkehr gleichmäßig auf alle verfügbaren Instanzen, um eine Überlastung einzelner Ressourcen zu verhindern. Wichtig dabei ist, die richtigen Metriken für die Skalierung auszuwählen. Bei Video-Transcoding-Anwendungen ist beispielsweise die Queue Depth oft aussagekräftiger als die CPU-Auslastung.
Vermeidung von Ressourcenverschwendung
Elastische Systeme passen die Ressourcen dynamisch an die aktuelle Nachfrage an. So wird vermieden, dass zu viele Ressourcen bereitgestellt werden, was unnötige Kosten verursacht, oder zu wenige, was zu Ausfällen führen könnte . Diese Fähigkeit, die optimale Menge an Ressourcen in Echtzeit bereitzustellen, erweist sich insbesondere bei unvorhersehbaren Arbeitslasten als äußerst nützlich .
So implementieren Sie elastische Ressourcenverteilung
Nachdem wir die Theorie der elastischen Ressourcenverteilung betrachtet haben, geht es jetzt um die praktische Umsetzung. Eine solide Infrastruktur bildet die Grundlage. Starten Sie mit einem Instance Template – einem Blueprint, der Maschinentyp, Boot-Disks und Startup-Skripte definiert. Diese Standardisierung garantiert, dass jede neue Instanz exakt gleich konfiguriert ist.
Infrastruktur und Voraussetzungen
Für die technische Umsetzung stehen verschiedene Optionen zur Verfügung: virtuelle Maschinen, Container (z. B. Amazon ECS oder EKS) oder serverlose Dienste wie AWS Lambda. Organisieren Sie diese Ressourcen in verwaltbare Einheiten, beispielsweise Managed Instance Groups. Ein Load Balancer sorgt dafür, dass eingehender Traffic gleichmäßig auf die dynamisch skalierenden Ressourcen verteilt wird. Um Ausfälle während der Skalierung zu vermeiden, sollten die Ressourcengruppen auf mehrere Zonen verteilt werden.
Vor der Implementierung ist eine Workload-Analyse entscheidend. Nicht alle Anwendungen sind für Elastizität geeignet. Systeme mit langen Startzeiten, Anforderungen an Session-Persistenz oder restriktiven Lizenzmodellen könnten ungeeignet sein. Anwendungen sollten möglichst zustandslos (stateless) sein, damit jede Instanz beliebige Anfragen bearbeiten kann, ohne lokale Session-Daten zu benötigen.
Konfiguration und Best Practices
Die Wahl der richtigen Skalierungsmetriken ist ein zentraler Erfolgsfaktor. Verlassen Sie sich nicht nur auf die CPU-Auslastung. Stattdessen sind workload-spezifische Kennzahlen oft hilfreicher. Bei Video-Transcoding-Anwendungen ist beispielsweise die Queue Depth eine aussagekräftigere Metrik als die CPU-Auslastung. Mit Predictive Autoscaling können Sie historische Daten nutzen, um Ressourcen vor einer erwarteten Lastspitze bereitzustellen, anstatt erst nach einem Leistungsabfall zu reagieren.
Um Startzeiten zu minimieren, setzen Sie auf „Golden Images“ – vorkonfigurierte Amazon Machine Images – oder Docker-Container, die neue Ressourcen schneller bereitstellen. Manuelle Kapazitätserhöhungen sollten vermieden werden. Stattdessen ist es sinnvoll, Automatisierungsregeln so zu optimieren, dass Alarme automatisch verarbeitet werden. Für Nicht-Produktionsumgebungen empfiehlt es sich, diese außerhalb der Hauptzeiten automatisch herunterzufahren.
Wenn die Konfiguration abgeschlossen ist, stellen Monitoring und Load Balancing sicher, dass das System stets leistungsfähig bleibt.
Monitoring und Load Balancing
Telemetrie-Tools spielen eine Schlüsselrolle, indem sie Logs, Metriken und Traces sammeln, um die Systemgesundheit zu überwachen. Der Load Balancer führt regelmäßige Health Checks durch und leitet Traffic automatisch von fehlerhaften Instanzen weg. Besonders wichtig ist das Testen von Scale-Down-Szenarien, um sicherzustellen, dass Verbindungen sauber beendet werden, bevor Instanzen entfernt werden. Legen Sie klare Mindest- und Höchstgrenzen für Instanzen fest, um sowohl unnötige Kosten als auch Leistungseinbußen zu vermeiden.
Elastizität vs. Skalierbarkeit: Die wichtigsten Unterschiede
Nachdem wir uns intensiv mit der Funktionsweise elastischer Ressourcenverteilung beschäftigt haben, beleuchtet dieser Abschnitt die Unterschiede zwischen Elastizität und Skalierbarkeit.
Definitionen und Konzepte
Elastizität beschreibt die Fähigkeit eines Systems, Ressourcen in Echtzeit automatisch anzupassen – sowohl nach oben als auch nach unten –, um kurzfristige Schwankungen in der Arbeitslast zu bewältigen. Das System reagiert dynamisch auf Veränderungen der Nachfrage, indem es Ressourcen hinzufügt oder reduziert, je nach Bedarf.
Skalierbarkeit hingegen bezieht sich auf die Fähigkeit eines Systems, langfristig wachsende Arbeitslasten zu bewältigen, indem zusätzliche Ressourcen bereitgestellt werden. Dies erfolgt in der Regel im Rahmen einer geplanten Strategie zur Kapazitätserweiterung. Während Elastizität kurzfristig wie ein Gummiband flexibel reagiert, gleicht Skalierbarkeit eher einem langfristigen Aufbauprozess.
Zusammengefasst: Elastizität sorgt für eine flexible Anpassung innerhalb bestehender Kapazitätsgrenzen und hilft dabei, Kosten zu optimieren und Überprovisionierung zu vermeiden. Skalierbarkeit hingegen stellt sicher, dass ein System auf zukünftiges Wachstum vorbereitet ist, sei es durch mehr Nutzer, größere Datenmengen oder höhere Transaktionszahlen. Diese Unterschiede werden in der folgenden Tabelle verdeutlicht.
Vergleichstabelle: Elastizität vs. Skalierbarkeit
| Merkmal | Cloud-Elastizität | Cloud-Skalierbarkeit |
|---|---|---|
| Zeitrahmen | Kurzfristig, unmittelbar, Echtzeit | Langfristig und geplant |
| Hauptziel | Effizienz und Kostenoptimierung | Unterstützung von Geschäftswachstum |
| Auslöser | Plötzliche, unvorhersehbare Schwankungen | Geplante Zunahme von Nutzern/Daten |
| Skalierungsmethode | Automatisiert (Auto Scaling) | Manuell oder vorab geplant |
| Permanenz | Dynamische Anpassung der Ressourcen | Dauerhafte Erweiterung der Kapazität |
| Kostenmodell | Nutzungsbasiert (Pay-as-you-use) | Geplante Budgetanpassungen |
| Anwendungsfall | Kurzfristige Spitzen (z. B. Black Friday) | Langfristige Wachstumsstrategien |
Ein praktisches Beispiel: Für eine E-Commerce-Plattform bedeutet Elastizität, während eines Black-Friday-Verkaufs automatisch das Zehnfache der üblichen Serverkapazität bereitzustellen und diese nach dem Event wieder abzubauen. Skalierbarkeit hingegen würde bedeuten, die Serverkapazität jährlich zu erhöhen, um eine wachsende internationale Kundschaft langfristig zu bedienen. Dieses Verständnis ist entscheidend, um Ressourcen optimal zu nutzen, sei es bei plötzlichen Traffic-Spitzen oder bei anhaltendem Wachstum.
Fazit
Die elastische Ressourcenverteilung ist aus modernen Cloud-Infrastrukturen nicht mehr wegzudenken. Sie ermöglicht es, Rechenressourcen wie CPU, RAM und Speicher dynamisch und in Echtzeit an wechselnde Arbeitslasten anzupassen – und das ganz ohne manuelles Eingreifen. Das AWS Well-Architected Framework bringt es auf den Punkt:
„Elasticity is the ability to acquire resources as you need them and release resources when you no longer need them. In the cloud, you want to do this automatically."
Diese Dynamik sorgt nicht nur für technische Effizienz, sondern bringt auch handfeste wirtschaftliche Vorteile mit sich. Unternehmen zahlen lediglich für die Ressourcen, die sie tatsächlich nutzen, vermeiden Leistungseinbußen bei Lastspitzen und minimieren das Risiko von Über- oder Unterprovisionierung.
Automatisierung spielt dabei eine zentrale Rolle: Systeme reagieren automatisch auf Metriken wie CPU-Auslastung, Speicherverbrauch oder Warteschlangentiefe. Manuelle Eingriffe widersprechen dem Prinzip der Elastizität und sollten vermieden werden. Dabei ist es wichtig, nicht nur das Hochskalieren, sondern auch das Herunterskalieren regelmäßig zu testen, um echte Kosteneinsparungen zu erzielen.
Für Unternehmen mit schwankenden Arbeitslasten – etwa E-Commerce-Plattformen während saisonaler Spitzen oder Streaming-Dienste mit variierendem Nutzeraufkommen – ist Elastizität unverzichtbar. Sie sorgt für mehr Effizienz und entlastet IT-Teams, die sich so auf strategisch wichtigere Aufgaben konzentrieren können.
Um wettbewerbsfähig zu bleiben, sollte die elastische Ressourcenverteilung ein fester Bestandteil jeder Cloud-Strategie sein. In Kombination mit Load Balancing, präzisem Monitoring und gegebenenfalls prädiktivem Autoscaling entsteht eine agile, kosteneffiziente und leistungsstarke IT-Infrastruktur. Die hier vorgestellten Ansätze lassen sich direkt umsetzen und bieten Unternehmen einen messbaren Vorteil im Wettbewerb.
FAQs
Was ist der Unterschied zwischen elastischer Ressourcenverteilung und traditioneller Skalierung?
Elastische Ressourcenverteilung bedeutet, dass Rechenleistung, Arbeitsspeicher und Speicherplatz automatisch und in Echtzeit an die aktuelle Arbeitslast angepasst werden. Die Cloud-Plattform überwacht dabei Kennzahlen wie die CPU-Auslastung oder den Netzwerkverkehr und passt die benötigten Ressourcen dynamisch an – ganz ohne manuelles Eingreifen. So wird vermieden, dass zu viele oder zu wenige Ressourcen bereitgestellt werden, und es fallen nur Kosten für die tatsächlich genutzten Kapazitäten an.
Im Gegensatz dazu erfolgt die traditionelle Skalierung entweder manuell oder nach festgelegten Regeln. Dabei gibt es zwei Ansätze: vertikales Skalieren, bei dem beispielsweise leistungsstärkere Server eingesetzt werden, und horizontales Skalieren, bei dem zusätzliche Server hinzugefügt werden. Dieser Prozess erfordert oft eine sorgfältige Planung und kann Verzögerungen oder sogar Ausfallzeiten mit sich bringen. Während Skalierbarkeit allgemein die Fähigkeit beschreibt, auf steigende Anforderungen zu reagieren, steht Elastizität für die automatisierte und flexible Umsetzung dieser Reaktionen.
Wie unterstützen Automatisierungs-Tools die elastische Ressourcenverteilung in der Cloud?
Automatisierungs-Tools sind unverzichtbar, wenn es um die flexible Verteilung von Ressourcen geht. Sie überwachen kontinuierlich Metriken wie CPU-Auslastung oder Netzwerktraffic und passen die Ressourcen automatisch an. Das bedeutet: keine manuelle Eingabe durch Administratoren und eine Skalierung, die in Echtzeit erfolgt.
Es gibt zwei wesentliche Ansätze für die Skalierung:
- Horizontale Skalierung: Hier werden Instanzen hinzugefügt oder entfernt, um die Leistung zu erhöhen oder zu verringern.
- Vertikale Skalierung: Dabei werden Ressourcen wie CPU oder Speicher innerhalb einer bestehenden Instanz angepasst.
Moderne Tools kombinieren oft zwei Skalierungsstrategien: dynamische Skalierung, die auf aktuelle Lastspitzen reagiert, und prädiktive Skalierung, die historische Daten auswertet, um zukünftige Anforderungen vorherzusehen.
Die Automatisierung bringt klare Vorteile: Sie verkürzt die Reaktionszeit, reduziert das Risiko menschlicher Fehler und optimiert die Kosten. Unternehmen zahlen nur für die Ressourcen, die sie tatsächlich nutzen, was sowohl die Kosteneffizienz als auch die Verfügbarkeit in Cloud-Umgebungen deutlich verbessert.
Warum ist die elastische Ressourcenverteilung in der Cloud für Unternehmen mit schwankenden Arbeitslasten wichtig?
Elastische Ressourcenverteilung bedeutet, dass Cloud-Systeme ihre Rechenleistung, ihren Speicher und ihre Kapazitäten automatisch an die aktuelle Arbeitslast anpassen. Wenn die Nachfrage steigt, werden zusätzliche Ressourcen bereitgestellt, und bei geringerer Auslastung werden diese wieder reduziert. Der Clou dabei: Unternehmen zahlen nur für die tatsächlich genutzten Ressourcen. So lassen sich unnötige Kosten vermeiden.
Gerade für Unternehmen mit stark schwankenden Arbeitslasten bringt das klare Vorteile mit sich. Kosteneffizienz steht dabei an erster Stelle, da keine überflüssigen Kapazitäten bezahlt werden müssen. Gleichzeitig sorgt die Zuverlässigkeit dafür, dass Anwendungen auch bei plötzlichen Spitzen – etwa während Black-Friday-Aktionen – reibungslos verfügbar und leistungsfähig bleiben. Ein weiterer Pluspunkt: Die automatische Skalierung senkt den Verwaltungsaufwand erheblich, sodass IT-Teams mehr Zeit für strategisch wichtige Aufgaben haben.
Mit dieser Flexibilität können Unternehmen nicht nur schnell auf Marktveränderungen reagieren, sondern auch ihre Betriebskosten besser im Griff behalten.
Verwandte Blogbeiträge
- Markttrends 2025: Logistikkosten reduzieren
- Checkliste für energieeffiziente Skalierung in Cloud-Umgebungen
- Wie Cloud-Analysen Speicherkosten senken
- Top 7 Tipps für Cloud-Preisverhandlungen