
API-Integrationen sind der Schlüssel für effiziente Berichtsprozesse, doch häufige Fehler können Systeme ausbremsen oder sogar lahmlegen. Hier sind die fünf größten Probleme und wie du sie vermeidest:
- Fehlerbehandlung fehlt: Ohne klare Fehlerstrategien führen kleine Probleme zu großen Systemausfällen.
- Rate Limiting ignoriert: Überlastete APIs liefern fehlerhafte oder unvollständige Daten.
- Schwache Sicherheit: Unzureichender Schutz öffnet Tür und Tor für Datenmanipulation.
- Keine Performance-Optimierung: Langsame Abfragen und Timeouts stören den Datenfluss.
- Veraltete Dokumentation: Unklare oder falsche API-Daten erschweren die Integration.
Lösung: Nutze bewährte Methoden wie Retries, Caching, OAuth 2.0 und asynchrone Prozesse. Halte Dokumentationen aktuell und setze auf API-Management-Tools, um Stabilität und Skalierbarkeit sicherzustellen.
Ein gut durchdachtes API-Design spart Zeit, reduziert Fehler und sorgt für zuverlässige Berichte – ein Muss für datengetriebene Unternehmen.
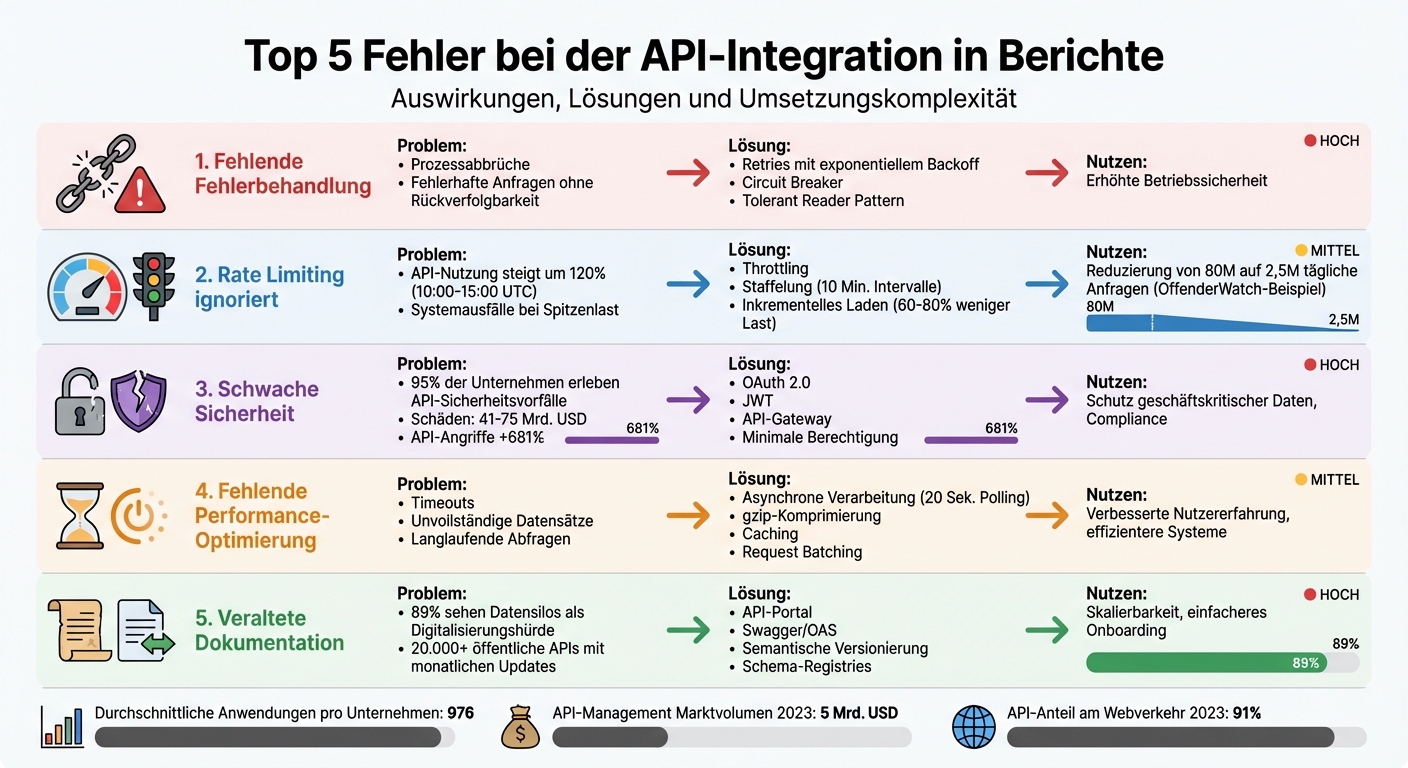
Die 5 häufigsten API-Integrationsfehler: Auswirkungen, Lösungen und Komplexität im Vergleich
1. Fehlende oder unzureichende Fehlerbehandlung
Auswirkungen auf die Genauigkeit und Funktionalität von Berichten
Eine unzureichende Fehlerbehandlung kann weitreichende Folgen haben. Bereits ein einzelner API-Fehler kann eine Kettenreaktion auslösen, die die Qualität von Berichten erheblich beeinträchtigt. Ein Beispiel: Wenn eine API-Anfrage aufgrund eines nicht unterstützten Dateiformats oder einer zu niedrigen Auflösung abgelehnt wird und die Fehlermeldung nicht korrekt verarbeitet wird, bleiben wichtige Daten unvollständig. Das Ergebnis? Berichte mit Lücken, die ihre Aussagekraft mindern. Besonders kritisch wird es bei asynchronen Prozessen: Ein unbehandelter Timeout kann dazu führen, dass Daten dauerhaft fehlen.
Um solche Probleme zu vermeiden, sind bewährte Muster und Strategien für die Fehlerbehandlung unerlässlich.
Lösungen einfach umsetzen
Moderne Systeme setzen auf erprobte Ansätze, um Fehler effizient zu handhaben. Ein Beispiel ist das Konzept der Retries mit exponentiellem Backoff. Hierbei wartet das System nach jedem Fehlversuch etwas länger, was viele temporäre Probleme automatisch behebt. Ein weiteres hilfreiches Werkzeug ist der Circuit Breaker: Er unterbricht vorübergehend Anfragen an einen ausgefallenen Service, um das Gesamtsystem zu schützen. Das Tolerant Reader Pattern geht noch einen Schritt weiter, indem es unbekannte Eigenschaften in einer JSON-Antwort ignoriert, anstatt das System abstürzen zu lassen.
Zusätzlich sollten spezifische Ausnahmefälle während der Integration durch gezielte Tests abgedeckt werden. Solche Maßnahmen verbessern nicht nur die Stabilität, sondern minimieren auch den Aufwand bei der Fehlersuche.
Langfristige Skalierbarkeit und Leistung
Neben der unmittelbaren Fehlerbehandlung spielt auch die Skalierbarkeit eine zentrale Rolle. Stefan Hilpp von SEEBURGER beschreibt die Herausforderung treffend:
"By changing the transfer method... to synchronous API, a direct reaction in real time becomes possible. However, this means that the error messages are just bounced back... the service consumer (the calling system) has to take care of further error handling."
Bei synchronen APIs liegt die Verantwortung für die Fehlerbehandlung vollständig beim aufrufenden System. Für komplexe Berichte ist jedoch ein asynchroner Workflow oft die bessere Wahl. Hierbei wird der Bericht angefordert, der Status regelmäßig geprüft (z. B. alle 20 Sekunden) und die fertigen Daten anschließend abgerufen. Die Verwendung standardisierter HTTP-Statuscodes wie 401, 429 oder 422 sorgt dabei für einheitliche und nachvollziehbare Reaktionen.
SEEBURGER bringt es auf den Punkt:
"APIs, if unmanaged, are the primary cause of business vulnerability that can result in high costs."
Ob synchron oder asynchron – beide Ansätze tragen dazu bei, die Stabilität und Zuverlässigkeit von Systemen zu gewährleisten.
2. Ignorieren von Rate Limiting und Throttling
Auswirkungen auf die Genauigkeit und Funktionalität von Berichten
Wer Rate Limits ignoriert, läuft Gefahr, unvollständige Datensätze zu erhalten, was die Genauigkeit von Berichten erheblich beeinträchtigen kann. Wird das API-Kontingent überschritten, führen Fehler wie HTTP 429 (Too Many Requests) oder 503 (Service Unavailable) zu veralteten und unvollständigen Berichten. Besonders zwischen 10:00 und 15:00 Uhr UTC, wenn die API-Nutzung um bis zu 120 % ansteigt, tritt häufiges Throttling auf. Werden in diesen Stoßzeiten Header wie „X-RateLimit-Reset“ ignoriert, können Verzögerungen auftreten, die letztlich das Vertrauen der Nutzer in Business-Intelligence-Systeme untergraben. Um diese Probleme zu vermeiden, sind gezielte Maßnahmen zur Verwaltung von API-Kontingenten unerlässlich.
Praktische Lösungen zur Problembewältigung
Mit durchdachten Strategien lassen sich viele dieser Herausforderungen effektiv lösen. Eine Kombination aus exponentiellem Backoff und der Nutzung von Retry-After-Headern kann Ausfallzeiten um 35 % reduzieren, während die Stabilität von Berichtsaktualisierungen auf 92 % steigt. Ein weiterer Ansatz ist das Staffeln von Synchronisationszeiten: Werden Berichte gleichzeitig synchronisiert, verlängern sich die Antwortzeiten um ein Vielfaches. Eine zeitliche Staffelung von mindestens 10 Minuten kann die Warteschlangentiefe um bis zu 40 % verringern. Zusätzlich können native Konnektoren mit automatischer Drosselung die Aktualisierungsdauer um bis zu 60 % verkürzen.
Langfristige Skalierbarkeit und Leistung
Für ein nachhaltiges Wachstum ist es entscheidend, inkrementelle Ladevorgänge einzusetzen. Statt komplette Datensätze zu übertragen, sollten nur neue oder geänderte Einträge abgerufen werden. Dies reduziert die Netzwerklast bei großen Datenquellen um 60 bis 80 % und schont gleichzeitig das API-Kontingent. Bei besonders umfangreichen Berichten ist es sinnvoll, den Bericht zunächst anzufordern, den Status abzufragen und anschließend die fertigen Daten abzurufen. So lassen sich Timeouts vermeiden.
DataDome bringt es treffend auf den Punkt:
"API rate limiting is no longer optional - it's essential infrastructure protection."
Ein reales Beispiel liefert die Organisation OffenderWatch: CEO Josh Bruner führte 2023 gezieltes Rate Limiting ein, um Scraping-Angriffe zu verhindern. Dadurch sanken die täglichen API-Anfragen von 80 Millionen auf 2,5 Millionen. Das Team spart nun 2 bis 3 Stunden tägliche Log-Überwachung, und die Infrastrukturkosten wurden erheblich gesenkt. Aus einer zuvor ausgebeuteten Ressource wurde ein profitables Produkt.
3. Schwache Authentifizierung und Sicherheitsmaßnahmen
Auswirkungen auf die Genauigkeit und Funktionalität von Berichten
Sicherheitslücken in der API-Integration sind nicht nur ein Risiko für sensible Daten – sie können auch die Integrität der Berichte gefährden. Angriffe wie SQL-Injections ermöglichen es, Daten zu manipulieren und dadurch Berichte zu verfälschen. Besonders problematisch ist die sogenannte Broken Object Level Authorization (BOLA). Hier wird die Zugriffsberechtigung nicht ausreichend überprüft, was Angreifern erlaubt, durch Manipulation einer Nutzer-ID unautorisiert auf Berichtsdaten zuzugreifen. Die Zahlen zeigen die Dringlichkeit: Innerhalb eines Jahres erlebten 95 % der Unternehmen einen API-Sicherheitsvorfall, wobei die geschätzten Schäden zwischen 41 und 75 Milliarden US-Dollar liegen.
Ein weiteres großes Problem ist die übermäßige Datenexposition. APIs liefern oft mehr Daten zurück, als tatsächlich benötigt werden, was vertrauliche Informationen unnötig offenlegt. Während der API-Verkehr allein im Jahr 2021 um 321 % anstieg, wuchs die Zahl der Angriffe auf APIs sogar um 681 %. Bis 2023 machten APIs bereits 91 % des gesamten Webverkehrs aus. Schwächen bei der Authentifizierung – wie unsichere Signaturen oder nicht überprüfte Token – eröffnen Angreifern die Möglichkeit, sich als legitime Nutzer auszugeben und Berichtsparameter zu manipulieren.
Praktische Lösungen zur Problembewältigung
Um APIs sicher zu integrieren, sollten Standards wie OAuth 2.0 und JSON Web Tokens (JWT) genutzt werden. Ein zentrales API-Gateway übernimmt dabei eine Schlüsselrolle: Es setzt Sicherheitsrichtlinien durch, verschlüsselt Daten und steuert den Traffic. Eine gründliche Validierung und Bereinigung aller Eingabeparameter ist unverzichtbar, um Angriffe wie SQL-Injections zu verhindern. Das Prinzip der minimalen Berechtigung ist ebenfalls essenziell – Nutzer sollten nur auf Daten zugreifen können, die für sie ausdrücklich freigegeben sind.
Automatisierte Tools, die alle aktiven APIs erfassen, helfen dabei, sogenannte „Shadow APIs“ zu identifizieren. Diese werden oft übersehen und verpassen wichtige Sicherheitsupdates. Obwohl 2021 nur 4,3 % der Entwickler Sicherheitstests durchführten, während 29,5 % funktionale Tests priorisierten, ist die Integration automatisierter Sicherheitstests in den API-Lebenszyklus heutzutage unerlässlich. Neben der Sicherheit trägt dies auch zur Skalierbarkeit des Berichtssystems bei.
Langfristige Skalierbarkeit und Leistung
Eine solide Authentifizierung erleichtert nicht nur die Sicherheit, sondern ermöglicht auch ein gezieltes Traffic-Management. Durch Maßnahmen wie gezielte Drosselung wird verhindert, dass Systemressourcen überlastet werden. Standards wie JWT oder OAuth 2.0 unterstützen eine zustandslose Kommunikation, was bedeutet, dass Server keinen Sitzungsstatus speichern müssen. Das macht es einfacher, Berichtssysteme horizontal zu skalieren.
Ein API-Gateway kann ressourcenintensive Authentifizierungsaufgaben zentral übernehmen, wodurch die Backend-Systeme entlastet werden. Diese können sich dann auf ihre Kernaufgaben konzentrieren, wie die Datenverarbeitung und Berichtserstellung. Zusätzlich verbessert Caching für häufig genutzte Berichtsdaten die Performance und reduziert die Belastung langsamer Backend-Systeme. Die Kombination aus Authentifizierung und Rate Limiting sorgt für eine faire Ressourcenverteilung und garantiert die Stabilität des Systems – ein entscheidender Vorteil, wenn das System wächst.
4. Fehlende Performance-Optimierung und Timeout-Konfiguration
Auswirkungen auf die Genauigkeit und Funktionalität von Berichten
Eine fehlende Performance-Optimierung kann dazu führen, dass Berichte nicht erfolgreich erstellt werden. Besonders kritisch wird es, wenn Timeout-Einstellungen zu kurz bemessen sind. In solchen Fällen unterbricht die Client-Anwendung die Verbindung, bevor der Bericht vollständig generiert ist. Das Resultat? Fehlgeschlagene Anfragen und keine nutzbaren Daten.
Auch langlaufende Abfragen können durch unzureichende Timeout- und Performance-Einstellungen blockiert werden. Wird die Verbindung bei der Übertragung großer Datenmengen unterbrochen, entstehen unvollständige Datensätze. Diese beeinträchtigen die Genauigkeit des Endberichts erheblich. Solche Herausforderungen beim Timeout-Management stehen in direktem Zusammenhang mit den bereits erwähnten Problemen bei der API-Integration.
Praktische Lösungen zur Problembewältigung
Ein Ansatz zur Lösung dieses Problems ist die Einführung der asynchronen Verarbeitung. Seit November 2025 setzt ein führender Anbieter auf dieses Verfahren, um Netzwerk-Timeouts zu vermeiden. Der Prozess beginnt mit einer POST-Anfrage, bei der ein HTTP-Status „202 ACCEPTED" und ein „Location"-Header zurückgegeben werden. Ein Polling-Intervall von 20 Sekunden hat sich bewährt, um langlaufende Datenabfragen, die mehrere Minuten dauern können, asynchron zu verarbeiten.
Zusätzlich lässt sich die Performance durch gezielte Maßnahmen steigern:
- Field Filtering: Mithilfe von Parametern wie „fields“ kann die Datenmenge reduziert werden, indem nur relevante Attribute abgerufen werden.
- gzip-Komprimierung: Diese Methode verkürzt die Antwortzeiten, insbesondere bei hohem Datenverkehr.
- ETags: In Kombination mit dem „If-None-Match“-Header wird verhindert, dass unveränderte Berichtsdaten erneut abgerufen werden. Ein Beispiel: Die Facebook Insights API aktualisiert ihre Statistikwerte alle 15 Minuten, wobei Änderungen bis zu 28 Tage nach dem ersten Bericht möglich sind.
Langfristige Skalierbarkeit und Performance
Neben kurzfristigen Lösungen spielt die langfristige Skalierbarkeit eine entscheidende Rolle. Eine Trennung der Datenerfassungs- und Verarbeitungsschichten ermöglicht es, beide Komponenten unabhängig voneinander zu skalieren.
Weitere Optimierungsansätze umfassen:
- Request Batching: Mehrere Anfragen werden in einem einzigen Batch-Aufruf zusammengefasst, wodurch der Netzwerk-Overhead deutlich reduziert wird.
- Caching-Strategien: Häufig angeforderte Daten werden zwischengespeichert, um redundante API-Aufrufe zu vermeiden.
- Echtzeitüberwachung von Throttle-Headern: Header wie „x-fb-ads-insights-throttle“ ermöglichen es, die Ressourcennutzung bei Überlastung sofort zu drosseln.
Technologien wie Serverless Computing, Auto-Scaling und verteilte Verarbeitungs-Frameworks – etwa Apache Spark – schaffen zusätzliche Kapazitäten und unterstützen das Wachstum auf Unternehmensebene.
5. Veraltete Dokumentation und Probleme beim Versionsmanagement
Neben der Fehlerbehandlung, dem Rate Limiting und der Performanceoptimierung wird die Bedeutung von Dokumentation oft unterschätzt – ein Fehler, der schwerwiegende Folgen haben kann.
Auswirkungen auf die Genauigkeit und Funktionalität von Berichten
Veraltete API-Dokumentation führt häufig zu Integrationsproblemen. Werden falsche Endpunkte, Parameter oder Datenstrukturen verwendet, sind fehlerhafte API-Aufrufe und ungenaue Berichte die Folge.
Ein Beispiel: Die Werk24 API verlangt für den Fehlercode CONFIGURATION_INCORRECT mindestens Version 2.3.0. Ohne diese Information wird die Fehlersuche schnell zur Herausforderung. Auch undokumentierte Änderungen an Datenformaten, Feldtypen oder JSON/XML-Strukturen können Parsing-Fehler verursachen, die die Genauigkeit von Berichten erheblich beeinträchtigen.
Laut einer Umfrage sehen 89 % der IT-Entscheider Datensilos und mangelnde Integration als zentrale Hindernisse für die Digitalisierung. Mit über 20.000 öffentlichen APIs und hunderten monatlichen Updates wird das Versionsmanagement für Unternehmen zu einer enormen Aufgabe.
Praktische Lösungen zur Problembewältigung
Ein zentraler Ansatzpunkt ist die Einführung einer zentralisierten Dokumentation. Ein API-Portal bietet Entwicklern eine zentrale Anlaufstelle mit aktueller Dokumentation, Nutzungsrichtlinien und Live-Testumgebungen. Tools wie Swagger oder Laravel Request Docs können dabei helfen, die Dokumentation automatisch zu erstellen und stets aktuell zu halten – und das parallel zur Code-Entwicklung.
"Unmanaged APIs are not secure and cannot be reused efficiently... they are the primary cause of business vulnerability that can result in high costs." – SEEBURGER
Zusätzlich empfiehlt sich der Einsatz semantischer Versionierung, beispielsweise durch den x-api-version-Header. So wird die Kompatibilität klar definiert. Alte API-Versionen sollten zudem aktiv überwacht werden, um Abschalttermine besser mit der tatsächlichen Nutzung abzustimmen und unvorhergesehene Systemausfälle zu vermeiden.
Langfristige Skalierbarkeit und Performance
Für eine nachhaltige Lösung bietet sich das API-First-Prinzip an: Hierbei wird die API-Spezifikation vor Beginn der Entwicklung entworfen und mit allen Stakeholdern abgestimmt. Schema-Registries, wie sie von Confluent oder Red Hat angeboten werden, helfen dabei, Deserialisierungsfehler zu vermeiden, indem sie Nachrichtenstrukturen zentral verwalten.
Der Markt für API-Management wird 2023 auf ein Volumen von 5 Milliarden US-Dollar geschätzt – ein klares Zeichen für die wachsende Bedeutung professioneller Dokumentation. Unternehmen wie Amazon setzen bereits auf API-First-Strategien. Dadurch werden alle Funktionalitäten über gut dokumentierte und externe Schnittstellen bereitgestellt.
Diese Ansätze ergänzen bestehende Strategien und legen den Grundstein für eine stabile und zukunftssichere API-Integration in Berichtssystemen.
Vergleichstabelle
Auf Grundlage der beschriebenen Herausforderungen bietet die folgende Tabelle eine Übersicht über typische Fehler, deren Auswirkungen und mögliche Lösungen, ergänzt durch eine Einschätzung der Umsetzungskomplexität und des langfristigen Nutzens.
| Fehlertyp | Auswirkung auf das System | Lösungsansatz | Umsetzungskomplexität | Langfristiger Nutzen |
|---|---|---|---|---|
| Unzureichende Fehlerbehandlung | Prozessabbrüche; fehlerhafte Anfragen ohne Rückverfolgbarkeit. | Zentrale Fehlerbehandlung durch Integrationsplattform; Verlagerung der Logik auf die Consumer-Seite. | Hoch: Erfordert organisatorische und technische Anpassungen. | Erhöhte Betriebssicherheit und vollständige Nachverfolgbarkeit. |
| Ignorieren von Rate Limiting | Systemausfälle bei Spitzenlast; Überlastung des Providers; „Noisy Neighbor"-Effekte. | Implementierung von Throttling, Quotas und Spike Arrest. | Mittel: Technische Konfiguration am Gateway. | Vermeidung von Ausfällen und Möglichkeit zur Monetarisierung. |
| Schwache Sicherheitsmaßnahmen | Datenlecks; unbefugter Zugriff; hoher Aufwand für Berechtigungsprüfungen. | Einsatz von OAuth 2.0, JWT und Web Application Firewalls. | Hoch: Erfordert ein robustes Identity- und Access-Management. | Schutz geschäftskritischer Daten und Einhaltung von Compliance-Vorgaben. |
| Fehlende Performance-Optimierung | Langsame Datenabfragen; Ressourcenüberlastung; Timeouts bei großen Abfragen. | Nutzung von Caching, In-Memory-Verarbeitung und Trennung zeitkritischer Prozesse. | Mittel: Technische Optimierung des Datenflusses. | Verbesserte Nutzererfahrung und effizientere Systeme. |
| Veraltete Dokumentation/Versionierung | Hohe Wartungskosten; Produktionsausfälle durch Breaking Changes; Deserialisierungsfehler. | Einführung von API-Portalen, Nutzung von Swagger/OAS-Standards und Full Lifecycle Management. | Hoch: Erfordert kontinuierliche Pflege über den gesamten Lebenszyklus. | Skalierbarkeit und einfacheres Onboarding neuer Entwickler. |
Die Komplexität der Umsetzung variiert je nach Maßnahme. Während beispielsweise Traffic-Management-Lösungen wie Spike Arrest relativ unkompliziert eingerichtet werden können, stellen umfassende Sicherheitskonzepte und eine durchgängige Dokumentation größere Herausforderungen dar. Dennoch lohnt sich der Aufwand: 89 % der IT-Entscheider betrachten Datensilos und fehlende Integration als zentrale Hürden der Digitalisierung.
Diese Übersicht dient als Grundlage, um gezielt Optimierungen anzugehen und zukünftige Herausforderungen effizienter zu bewältigen.
Fazit
Fünf häufige Fehler bei API-Integrationen können die Zuverlässigkeit und Geschwindigkeit von Berichtssystemen erheblich beeinträchtigen: mangelhafte Fehlerbehandlung, ignoriertes Rate Limiting, unzureichende Sicherheitsmaßnahmen, fehlende Performance-Optimierung und veraltete Dokumentation. Wer diese Probleme umgeht, legt den Grundstein für stabile, skalierbare und sichere Reporting-Prozesse.
Wie bereits erwähnt, betrachten IT-Entscheider Datensilos als eines der größten Hindernisse bei der Digitalisierung. Gleichzeitig setzen Unternehmen durchschnittlich 976 Software-Anwendungen ein, von denen nur ein kleiner Teil tatsächlich miteinander verbunden ist. Durch optimierte API-Praktiken – wie asynchrone Verarbeitung, automatisiertes Monitoring und strikte Versionierung – lassen sich technische Schulden reduzieren und Betriebskosten deutlich senken.
In zeitkritischen Umgebungen ist eine professionelle Integration unverzichtbar. Die Trennung von Echtzeit-Anfragen und Batch-Prozessen minimiert Ressourcenkonflikte, während effiziente Caching-Mechanismen die Systemlast spürbar verringern. Diese Maßnahmen zeigen klar, wie gezielte Optimierungen den gesamten Reporting-Prozess verbessern können.
Julius von der Deutschen Bahn AG bringt es auf den Punkt:
„APIs bilden die Grundlage für neue digitale Geschäftsmodelle und Nutzergruppen – sie schaffen etwas Neues und profitieren gleichzeitig von dem, was bereits existiert."
Für Unternehmen wie die CUBEE Sachverständigen AG, die auf digitale Prozesse und schnelle Gutachten angewiesen sind, ist eine optimierte API-Integration entscheidend. Sie ermöglicht präzise Berichte in Echtzeit – ohne Verzögerungen oder Sicherheitsrisiken. Moderne Schnittstellen machen es möglich, Fahrzeugdaten, Schadensberichte und Wertgutachten nahtlos in bestehende Systeme zu integrieren und direkt zu verarbeiten.
Eine robuste API-Architektur bietet langfristige Vorteile: schnellere Reaktionszeiten, verbesserte Datenqualität und die Flexibilität, neue Funktionen wie KI-gestützte Analysen einfach zu implementieren.
FAQs
Wie kann ich meine API-Integrationen vor Sicherheitsrisiken schützen?
Um Sicherheitsrisiken bei API-Integrationen zu verringern, sollten Sie unbedingt die OWASP API Security Top 10 berücksichtigen. Diese umfassen wichtige Maßnahmen wie:
- Sichere Authentifizierungsmethoden: Setzen Sie auf Standards wie OAuth oder JWT, um den Zugriff sicher zu gestalten.
- Strenge Eingabevalidierung: Stellen Sie sicher, dass alle Eingaben gründlich überprüft werden, um Schwachstellen wie Injection-Angriffe zu vermeiden.
- Minimalprinzip bei Berechtigungen: Gewähren Sie nur die Rechte, die unbedingt erforderlich sind.
- Rate-Limiting: Begrenzen Sie die Anzahl der Anfragen, um Missbrauch und Überlastung zu verhindern.
- Kontinuierliche Überwachung: Behalten Sie den API-Verkehr im Blick, um verdächtige Aktivitäten frühzeitig zu erkennen.
- Regelmäßige Penetrationstests: Testen Sie Ihre APIs auf Schwachstellen, um Sicherheitslücken zu schließen.
Ein API-Gateway kann zusätzlich unterstützen, indem es Sicherheitsrichtlinien durchsetzt und Angriffe schneller erkennt. Kombinieren Sie diese Maßnahmen mit einer proaktiven Sicherheitsstrategie und regelmäßigen Updates Ihrer API-Integrationen, um langfristig einen soliden Schutz zu gewährleisten.
Wie kann man die Auswirkungen von Rate-Limiting bei der API-Integration in Berichte reduzieren?
Um die Auswirkungen von Rate-Limiting zu verringern, gibt es einige kluge Ansätze, die Sie in Betracht ziehen sollten:
- Automatisierte Wiederholungslogik mit Pausen: Nutzen Sie Techniken wie exponentielles Backoff, um Anfragen bei Überschreitung der Limits kontrolliert und mit wachsender Verzögerung erneut zu senden. Das hilft, Überlastungen zu vermeiden.
- Anfragen in kleinere Batches aufteilen: Zerlegen Sie große Datenanforderungen in kleinere Abschnitte und legen Sie zwischen den einzelnen Batches kurze Pausen ein. So wird die API-Nutzung gleichmäßiger verteilt.
- Limit-Header überwachen: Behalten Sie die von der API bereitgestellten Header im Blick. Sie geben Ihnen wertvolle Hinweise darauf, wie nah Sie an die festgelegten Grenzen kommen.
- Caching einsetzen: Speichern Sie häufig benötigte Daten lokal, um wiederholte API-Aufrufe zu reduzieren. Das spart nicht nur Ressourcen, sondern sorgt auch für schnelleren Zugriff.
Mit diesen Methoden optimieren Sie Ihre Systeme und bleiben gleichzeitig innerhalb der API-Beschränkungen. So arbeiten Ihre Berichterstellungsprozesse reibungslos und effizient.
Wie kann ich die API-Integration in meine Berichte effizient und langfristig verbessern?
Um die Leistung Ihrer API-Integrationen dauerhaft zu verbessern, ist ein durchdachtes Schnittstellendesign entscheidend. Es ist wichtig, regelmäßig Latenz- und Durchsatzwerte zu überprüfen, um mögliche Engpässe frühzeitig zu identifizieren. Mit Last- und Performance-Tests können Sie die Belastbarkeit Ihrer Systeme bewerten und potenzielle Schwachstellen gezielt beheben.
Zusätzlich lassen sich durch den Einsatz von Caching-Strategien und automatischer Skalierung deutliche Effizienzgewinne erzielen. Diese Ansätze stellen sicher, dass Berichte auch bei steigenden Datenmengen zuverlässig und schnell erstellt werden. Ein kontinuierlicher Verbesserungsprozess spielt dabei eine zentrale Rolle, um langfristig stabile und leistungsfähige Ergebnisse zu gewährleisten.
Verwandte Blogbeiträge
- 5 häufige Schwachstellen in digitalen KFZ-Datenplattformen
- API-Schwachstellen in Standortsystemen verstehen
- API-Entwicklung für KFZ-Gutachten: Ein Leitfaden
- Top 3 Tools für Wettbewerber-Preisanalysen im Vergleich