
Betrug bei KFZ-Schadensbewertungen kostet Versicherungen Millionen. Manipulierte Fotos, falsche Angaben und fingierte Unfälle sind häufige Probleme. Künstliche Intelligenz (KI) hilft, diese Fälle effizient zu erkennen.
Was macht KI in diesem Bereich so nützlich?
- Bildanalyse: KI prüft Fotos auf Manipulationen und erkennt Schäden präzise.
- Metadatenprüfung: Zeitstempel, GPS-Daten und andere Details werden abgeglichen.
- Dokumentanalyse: Kostenvoranschläge und Gutachten werden auf Unstimmigkeiten geprüft.
- Anomalieerkennung: Verdächtige Muster wie wiederverwendete Fotos oder widersprüchliche Angaben werden markiert.
Vorteile:
- Zeitersparnis: Automatisierte Prüfungen reduzieren Bearbeitungszeiten um bis zu 50 %.
- Präzisere Ergebnisse: Betrugsfälle werden schneller und genauer identifiziert.
- Rechtssicherheit: DSGVO-konforme Prozesse und menschliche Endkontrollen garantieren Transparenz.
Mit KI können Versicherungen Schäden effizienter bearbeiten und betrügerische Ansprüche gezielt verhindern.
Daten als Grundlage der KI-Betrugserkennung
Hochwertige Daten sind das Fundament für den Erfolg von KI-Methoden zur Betrugserkennung. Die Qualität und Struktur der Eingangsdaten beeinflussen direkt die Zuverlässigkeit der Ergebnisse. Schon ein Anteil von 10–20 % fehlerhafter oder unvollständiger Daten kann die Erkennungsleistung der KI erheblich beeinträchtigen. Um die optimale Funktion der KI-Module sicherzustellen, müssen daher klare Datenstandards eingehalten werden.
Die wichtigsten Datenquellen für die KI-Analyse
Für die KI-gestützte Betrugserkennung spielen drei Datenkategorien eine zentrale Rolle: Bilddaten, Fahrzeug- und Kontext-Metadaten sowie historische Schadendaten.
- Bilddaten: Hochauflösende Fotos aus verschiedenen Blickwinkeln (Vorder-, Heck-, Seitenansichten und Detailaufnahmen) sind essenziell.
- Fahrzeug- und Kontext-Metadaten: Hierzu gehören Informationen wie die Fahrgestellnummer (FIN/VIN), Marke, Modell, Baujahr und Kilometerstand. Ergänzend liefern GPS-Koordinaten, Zeitstempel und die Geräte-ID der Kamera wichtige Kontextinformationen, die die Effizienz der KI-Analyse verbessern.
- Historische Schadendaten: Modelle, die auf Basis von Millionen früherer Schadensfälle trainiert wurden, können wiederkehrende Betrugsmuster erkennen. Beispiele hierfür sind „recycelte“ Schadensfotos, die mehrfach verwendet werden, oder auffällige Häufungen kleinerer Schäden kurz vor Vertragsänderungen.
Datenqualität und Konsistenz sicherstellen
Damit die Ergebnisse der KI nicht nur zuverlässig, sondern auch rechtlich belastbar sind, müssen strenge Qualitätsstandards eingehalten werden.
- Bildqualität: Fotos sollten eine Mindestauflösung von 8–12 Megapixeln haben und weder manipuliert noch schlecht belichtet sein. Fehlende oder manipulierte EXIF-Daten (wie GPS-Informationen) können als Betrugssignal gewertet werden und den Fraud-Score erhöhen.
- Auditierbarkeit: Jede Änderung an den Datensätzen muss dokumentiert und versioniert werden. Dadurch können KI-Entscheidungen im Streitfall vor Gerichten oder Aufsichtsbehörden nachvollzogen werden.
Digitale Workflows für Datenerfassung und -integration
Ein digitaler Erfassungsprozess ist entscheidend, um konsistente Daten für die KI-Analyse bereitzustellen. Geführte Workflows in Foto-Apps stellen sicher, dass alle relevanten Daten vollständig erfasst werden. Automatische Validierungen – wie Warnungen bei deaktiviertem GPS oder fehlerhaften Zeitstempeln – tragen zusätzlich zur Datenkonsistenz bei.
Ein Beispiel für solch einen Ansatz ist der digitalisierte Gutachtenprozess der CUBEE Sachverständigen AG. Standardisierte Eingabemasken und strukturierte Datenerfassung ermöglichen die Erstellung konsistenter Datensätze, die direkt in KI-Analysetools integriert werden können – ohne manuelle Zwischenschritte. Versicherer, die solche integrierten Prozesse nutzen, berichten von einer Verkürzung der durchschnittlichen Schadenbearbeitungszeit um 30–50 %, da unauffällige Fälle automatisiert bearbeitet und nur Verdachtsfälle an Experten weitergeleitet werden.
sbb-itb-d35113a
KI-Methoden zur Betrugserkennung bei KFZ-Schadensbewertungen
Mit hochwertigen Daten im Rücken kommen spezialisierte KI-Techniken zum Einsatz, die Fotos, Metadaten und Dokumente auf Auffälligkeiten untersuchen – schneller und präziser, als es manuell möglich wäre. Neben der Bildanalyse spielen auch Metadaten eine entscheidende Rolle.
Bildanalyse zur Betrugserkennung
Moderne KI-Systeme setzen auf Computer Vision, um Manipulationen in Schadensfotos aufzuspüren. Echtzeit-Objektdetektoren wie YOLO (You Only Look Once) erkennen und markieren Schadensbereiche wie Kratzer, Dellen oder Risse in Sekundenschnelle. Ein modifizierter YOLO-Detektor mit LRN erreicht dabei eine Erkennungsrate von 81,7 %.
Darüber hinaus kommen Convolutional Neural Networks (z. B. VGG16) zum Einsatz, die sogenannte „Deep Features“ extrahieren – eine Art digitaler Fingerabdruck des Schadens. Diese Netzwerke kombinieren lokale und globale Merkmale, um sicherzustellen, dass der Schaden tatsächlich zum gemeldeten Fahrzeug gehört. Dieser Ansatz konnte die Betrugserkennungsrate auf 56,52 % steigern, während die alleinige Nutzung globaler Merkmale lediglich 19,6 % erreichte. So lassen sich sowohl wiederverwendete Fotos als auch fremde Schadensbilder zuverlässig identifizieren.
Metadaten-Prüfung und Herkunftsnachweis
Neben den Bildinhalten bieten EXIF-Daten wertvolle Informationen. KI-Systeme gleichen automatisch Zeitstempel und GPS-Koordinaten aus den Bilddateien mit den Angaben im Schadensbericht ab. Weichen die Daten – etwa der Aufnahmeort – vom gemeldeten Unfallort ab, wird der Fraud-Score entsprechend erhöht.
Hierbei kommt Fuzzy-Logik ins Spiel, um Unstimmigkeiten zu gewichten. Ein GPS-Widerspruch wird beispielsweise stärker bewertet als andere Abweichungen. Wolfgang Färber, Teamleiter Schaden-/Leistungsregulierung IT der Nürnberger Versicherung, erklärt:
„Fuzzylogik hilft, überlappende Verdachtsbereiche zu definieren und Ergebniswerte mit unterschiedlicher Gewichtung zu interpretieren."
Dokumentenanalyse mit KI
Zusätzlich zur Bild- und Metadatenanalyse liefert die Dokumentenanalyse weitere Hinweise auf mögliche Manipulationen. Bei der Prüfung von Reparaturrechnungen und Kostenvoranschlägen kommen zwei Verfahren zum Einsatz: Error Level Analysis (ELA) und Bildvektorisierung.
ELA untersucht das Rauschverhalten digitaler Bilder. Manipulierte Bereiche – beispielsweise nachträglich eingefügte Zahlen oder Stempel – zeigen ein abweichendes Fehlerniveau. ResNet50 wandelt Bilder in numerische Vektoren um, die dann mit einer marktweiten Datenbank abgeglichen werden. Seit 2020 nutzt die Nürnberger Versicherung diesen Ansatz im System BUBE (Bildforensik Und BetrugsErkennung), das in Kooperation mit der Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) entwickelt wurde.
„BUBE analysiert eingereichte Schadenfotos auf Manipulationen und hilft so, betrügerische Ansprüche zu identifizieren und abzuwehren." – Wolfgang Färber, Nürnberger Versicherung
Ein großer Vorteil der Bildvektorisierung: Die erzeugten Vektoren enthalten keine personenbezogenen Daten und ermöglichen somit einen datenschutzkonformen, unternehmensübergreifenden Vergleich, um Betrug auch über Firmengrenzen hinweg aufzudecken. Durch die Kombination beider Techniken wird die Betrugserkennungsrate weiter optimiert.
KI-gestützte Mustererkennung bei Schadenmeldungen
Ein einzelnes auffälliges Foto oder eine verdächtige Rechnung kann ein Hinweis sein – aber erst durch die Fähigkeit der KI, Muster über viele Fälle hinweg zu erkennen, wird Betrugserkennung wirklich effektiv. Basierend auf den zuvor beschriebenen Daten- und Bildanalysen ermöglicht die KI eine systematische Analyse großer Datensätze, um betrügerische Aktivitäten gezielt aufzudecken. Im Folgenden wird erklärt, wie diese präzise Mustererkennung funktioniert und welche Betrugsmuster dabei häufig auftreten.
Wie Anomalieerkennung funktioniert
KI-Systeme lernen, was bei einer typischen Schadenmeldung als normal gilt: von den durchschnittlichen Schadenshöhen über übliche Reparaturzeiten bis hin zu plausiblen Unfallhergängen. Sobald ein Fall von diesen Mustern abweicht, schlägt das System Alarm. Dabei kommt häufig der Isolation Forest-Algorithmus zum Einsatz, der Anomalien schneller erkennt, da diese sich klar von normalen Mustern unterscheiden.
Für komplexere Betrugsmuster werden hybride Modelle genutzt, die generative Ansätze mit Klassifikatoren wie XGBoost kombinieren. Diese Methode ist besonders effektiv, da Betrugsfälle im Vergleich zu regulären Meldungen selten sind. XGBoost allein steigert die Präzision um 7 % im Vergleich zu klassischen Entscheidungsbaum-Modellen. Solche Anomalien weisen oft auf bestimmte wiederkehrende Betrugsmuster hin.
Typische Betrugsmuster bei KFZ-Schäden
Betrügerische Schadensmeldungen folgen oft ähnlichen Mustern, die sich mit KI zuverlässig aufdecken lassen:
- Same-Vehicle-Reclaim: Alte Schadensfotos werden erneut eingereicht, oft leicht verändert – etwa durch einen anderen Bildausschnitt oder Farbfilter.
- Cross-Vehicle-Reclaim: Fotos eines fremden Fahrzeugs, oft aus dem Internet, werden für eine eigene Schadenmeldung genutzt.
- Metadaten-Widersprüche: EXIF-Daten eines Fotos zeigen, dass es lange vor dem angeblichen Unfall aufgenommen wurde.
Besonders hilfreich ist hier die Bildvektorisierung. Sie ermöglicht einen datenschutzkonformen Vergleich von Fotos über viele Fälle hinweg und deckt so wiederholte Betrugsmuster zuverlässig auf.
KI-Anomalieerkennung in Gutachtenprozessen einbinden
Der praktische Nutzen der Anomalieerkennung wird besonders deutlich, wenn sie direkt in den Begutachtungsprozess integriert wird. Jeder Fall erhält automatisch einen Risiko-Score. Liegt dieser unter einem festgelegten Schwellenwert, wird die Meldung automatisiert bearbeitet. Überschreitet der Score den Schwellenwert, wird der Fall an einen Sachverständigen zur manuellen Prüfung weitergeleitet.
„Die Betrugsabwehr in der Versicherungsbranche steht oft im Konflikt mit dem Bestreben, den Versicherten schnellstmöglich ihre Leistungen zu gewähren." – Wolfgang Färber, Teamleiter Schaden-/Leistungsregulierung IT, Nürnberger Versicherung
Das Ziel ist ein ausgewogenes System: schnelle Bearbeitung für ehrliche Fälle, gezielte Prüfung bei Verdachtsfällen. So können Sachverständige ihre Zeit auf die wirklich kritischen Fälle konzentrieren, während die Mehrheit der Meldungen effizient abgewickelt wird.
KI in digitale Gutachtenprozesse integrieren
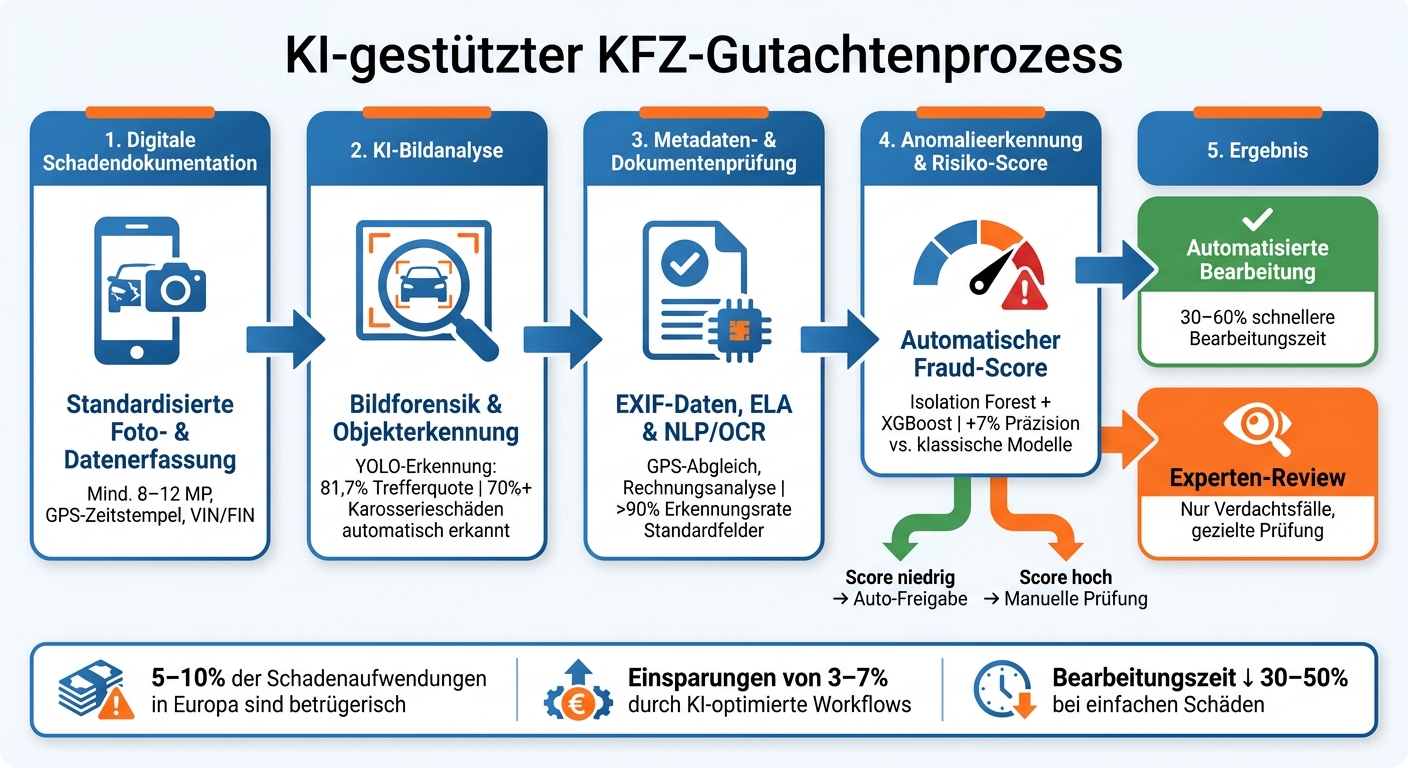
KI-gestützte Betrugserkennung bei KFZ-Schäden: Der automatisierte Workflow
Der Übergang zur vollständigen Integration von KI sollte schrittweise erfolgen, um Fehler und Widerstände innerhalb der Organisation zu minimieren. Dieser Ansatz baut auf bestehenden digitalen Datenerfassungsprozessen auf und ermöglicht einen nahtlosen Übergang zu vollständig KI-gestützten Gutachtenprozessen. Dabei wird nicht nur die zuvor erwähnte KI-gestützte Betrugserkennung verbessert, sondern auch der gesamte Gutachtenprozess effizienter gestaltet.
Schritt für Schritt zum KI-gestützten Workflow
Der Ausgangspunkt ist eine standardisierte, digitale Schadendokumentation, die sich an den bestehenden Datenstandards orientiert. Erst wenn diese Basis solide steht, lohnt sich der nächste Schritt.
Im weiteren Verlauf werden schrittweise KI-Bildanalyse, Dokumentenanalyse und Anomalieerkennung integriert. Diese Technologien übernehmen automatisierte Vorprüfungen, wie Vollständigkeits- und Plausibilitätschecks. Studien zeigen, dass durch diesen Ansatz die Bearbeitungszeit bei einfachen Schäden um 30 bis 60 % reduziert werden kann. Mit zunehmender Erfahrung und Daten können Standardfälle bis zu einem bestimmten Betrag (in €) vollständig automatisiert bearbeitet werden, ergänzt durch stichprobenartige menschliche Kontrollen.
Ein praktisches Beispiel bietet CUBEE: Fotos, die direkt am Container-Standort oder durch mobile Gutachter aufgenommen werden, fließen unmittelbar in das digitale System ein. Dort können sie automatisiert vorgeprüft werden – ohne Medienbrüche oder Softwarewechsel für die Sachverständigen. Das Ergebnis: Verdächtige Fälle werden effizienter erkannt und für eine manuelle Prüfung weitergeleitet.
Die wichtigsten KI-Module im Überblick
Nach der Implementierung der einzelnen Phasen bilden folgende Module den Kern des automatisierten Prozesses:
- Bildforensik und Objekterkennung: Diese Module klassifizieren die Schadensart und den Schweregrad auf Bauteilebene. Laut Anbieter Tractable erkennt deren Technologie über 70 % der gängigen Karosserieschäden automatisch und ordnet sie korrekt zu.
- Dokumenten-NLP mit OCR: Rechnungen und Kostenvoranschläge werden ausgelesen, wobei nach gezieltem Training Erkennungsraten von über 90 % für Standardfelder wie Rechnungsbeträge oder Ersatzteilnummern erreicht werden.
- Anomalieerkennung: Diese bewertet jeden Fall mit einem Risiko-Score. Auffällige Vorgänge werden automatisch zur manuellen Prüfung weitergeleitet.
Alle Module können als eigenständige Microservices über REST-APIs in bestehende Gutachter-Software integriert werden, ohne dass die IT-Infrastruktur vollständig erneuert werden muss.
Modellpflege, Datenschutz und Governance
Ein KI-Modell, das heute zuverlässig arbeitet, kann morgen bereits veraltet sein, da sich Betrugsmuster ständig weiterentwickeln. Deshalb benötigen Unternehmen MLOps-Prozesse, um Modelle regelmäßig anhand neuer Fälle und bestätigter Betrugsmuster zu aktualisieren. Ebenso wichtig ist Explainable AI (XAI): In Deutschland verlangen Regulatoren und Gerichte nachvollziehbare Entscheidungen. KI-Module sollten daher markierte Bildbereiche und erläuternde Texte bereitstellen, die der Sachverständige im Gutachten einsehen kann.
Für eine solide Governance empfiehlt sich die Einrichtung eines KI-Gremiums. Dieses sollte aus Fachbereichen, IT, Datenschutz und Compliance bestehen, um Schwellenwerte und Entscheidungsregeln zu dokumentieren. So wird sichergestellt, dass der Mensch dort entscheidet, wo es rechtlich und fachlich erforderlich ist.
Fazit: Was KI für KFZ-Schadensbewertungen bedeutet
Künstliche Intelligenz verändert die KFZ-Schadensbewertung grundlegend. In Europa wird geschätzt, dass 5–10 % der Schadenaufwendungen betrügerisch sind. KI-gestützte Systeme tragen dazu bei, diesen Anteil zu reduzieren, indem sie Prüfungen konsistenter gestalten, die Bearbeitungszeiten verkürzen und Betrugsfälle genauer erkennen. Einige InsurTech-Unternehmen berichten von Einsparungen zwischen 3 und 7 %, die durch optimierte Arbeitsabläufe und eine präzisere Betrugserkennung erzielt werden. Diese Ergebnisse verdeutlichen, wie KI Effizienz und Genauigkeit miteinander verbindet.
Obwohl KI die Arbeit von Sachverständigen nicht vollständig ersetzt, übernimmt sie Routineaufgaben wie die Bildanalyse zur Schadenerkennung oder die Auswertung von Dokumenten. Dadurch bleibt den Experten mehr Zeit für komplexe Fälle. Das Zusammenspiel aus menschlicher Expertise und algorithmischer Präzision schafft ein effektives System, das sowohl effizient arbeitet als auch hohe Qualitätsstandards gewährleistet – ein wichtiger Aspekt für den deutschen Markt.
In Deutschland spielen regulatorische Vorgaben wie die DSGVO, das VVG und der kommende EU AI Act eine zentrale Rolle. KI-Entscheidungen müssen transparent und nachvollziehbar sein. Explainable AI ist hier keine Option, sondern eine rechtliche Voraussetzung.
Ein anschauliches Beispiel liefert die CUBEE Sachverständigen AG. Durch einen digitalisierten Gutachtenprozess, der Container-Standorte und mobile Sachverständige einbindet, entsteht eine strukturierte Datenbasis. Diese Datenbasis ermöglicht es KI-Modulen, Aufgaben wie Bildanalysen, Anomalieerkennung und Dokumentenprüfungen zuverlässig durchzuführen. Das Ergebnis: schnelle, präzise und betrugssichere KFZ-Gutachten, ganz ohne Medienbrüche oder Verzögerungen.
FAQs
Wie hoch ist die Fehlalarmquote bei der KI-Betrugserkennung?
Moderne KI-Systeme haben die Fähigkeit, Fehlklassifikationen deutlich zu reduzieren. Durch den Einsatz von Meta-Klassifikationsmodellen konnte die Rate an falsch-positiven Ergebnissen bei Fahrzeugteilen um bis zu 77 % gesenkt werden. Fotos, die unscharf sind oder unter schlechten Lichtverhältnissen aufgenommen wurden, werden automatisch zur manuellen Überprüfung weitergeleitet. Das sorgt für eine spürbare Verbesserung der Genauigkeit. Die CUBEE Sachverständigen AG setzt diese Technologie ein, um sowohl vor Ort als auch mobil schnelle und präzise KFZ-Gutachten zu erstellen.
Welche Nachweise benötigt man, wenn EXIF-Daten fehlen?
Fehlen EXIF-Daten oder wurden sie manipuliert, ist die Beweissicherung trotzdem möglich. Entscheidend sind Fotos aus unterschiedlichen Perspektiven – sowohl Übersichtsbilder als auch Detailaufnahmen der Schäden. Mithilfe von KI-Systemen wie Perceptual Hashing (pHash) lassen sich Manipulationen oder doppelte Meldungen auch ohne Metadaten erkennen. Bei CUBEE ergänzen Fachleute die digitale Dokumentation durch technische Analysen, um eine rechtssichere Einschätzung sicherzustellen.
Wie wird der Fraud-Score-Schwellenwert festgelegt?
Der Fraud-Score-Schwellenwert wird durch präzise Qualitätsmetriken definiert, um eine hohe Zuverlässigkeit des Systems zu gewährleisten. Zwei der wichtigsten Kriterien sind ein Mindest-Recall von über 95 % sowie klar festgelegte Toleranzbereiche für Abweichungen bei Reparaturkosten.
CUBEE setzt auf eine Kombination aus modernster Technologie und umfangreichen Datenquellen. Dazu gehören:
- Digitalisierte Prozesse: Automatisierte Abläufe minimieren menschliche Fehler und erhöhen die Effizienz.
- Historische Datenbanken: Diese liefern wertvolle Vergleichsdaten für präzise Analysen.
- Fahrverhaltensdaten: Sie ermöglichen eine tiefere Einblicke und helfen, potenzielle Manipulationen zu identifizieren.
- Perceptual Hashing: Eine Methode, die durch objektive Analysen Manipulationen erheblich erschwert.
Durch diese Ansätze wird nicht nur die Systemintegrität gestärkt, sondern auch die Manipulationssicherheit signifikant erhöht.
Verwandte Blogbeiträge
- So funktioniert KI-gestützte Schadensbewertung
- Wie Gutachter strukturelle Schäden bewerten
- Studie: Wie digitale Tools KFZ-Gutachten verbessern
- Wie hilft KI bei der Erkennung von Betrug in KFZ-Gutachten?