
Künstliche Intelligenz (KI) verändert die Versicherungsbranche, bringt aber auch Risiken mit sich – insbesondere die Gefahr von Diskriminierung. Fehlerhafte Algorithmen können zu Benachteiligungen führen, indem sie Entscheidungen wie Prämienberechnungen oder Schadensregulierungen verzerren. Dies verstößt gegen das Allgemeine Gleichbehandlungsgesetz (AGG) in Deutschland und die EU-KI-Verordnung, die strenge Anforderungen an den Einsatz von Hochrisiko-KI-Systemen stellt.
Kernpunkte:
- Ursachen für Diskriminierung: Voreingenommene Trainingsdaten, fehlerhaftes Algorithmendesign und mangelnde Überwachung.
- Lösungsansätze: Nutzung repräsentativer Daten, Debiasing-Methoden wie FairGBM, erklärbare KI-Modelle, der Einsatz spezialisierter KI-Tools und regelmäßige Audits.
- Regulatorische Vorgaben: Die EU-KI-Verordnung fordert Transparenz, Überwachung und Sanktionen bei Verstößen (bis zu 15 Mio. € oder 3 % des Jahresumsatzes).
- Vorteile für Versicherer: Höhere Genauigkeit, Vermeidung von Bußgeldern und gestärktes Kundenvertrauen.
Versicherer müssen sicherstellen, dass ihre KI-Systeme diskriminierungsfrei arbeiten – nicht nur aus rechtlichen Gründen, sondern auch, um langfristig erfolgreich zu bleiben.
Warum KI-Algorithmen voreingenommen werden
KI-Systeme können Voreingenommenheiten übernehmen – sei es durch fehlerhafte Daten, problematische Entwicklungsentscheidungen oder mangelnde Überwachung.
Probleme mit Trainingsdaten
Die Qualität der Trainingsdaten ist entscheidend dafür, wie neutral oder voreingenommen ein KI-Modell agiert. Historische Verzerrungen entstehen, wenn Algorithmen aus Daten lernen, die bereits menschliche Vorurteile oder gesellschaftliche Ungleichheiten widerspiegeln. Ein bekanntes Beispiel ist das COMPAS-System, das in den USA zur Risikoeinschätzung in Gerichtsverfahren genutzt wurde. Laut einer ProPublica-Studie aus Mai 2016 überschätzte das System die Rückfallquote schwarzer Angeklagter. Die Ursache: Die Trainingsdaten spiegelten eine unverhältnismäßige Polizeipräsenz in bestimmten Stadtteilen wider, anstatt das tatsächliche individuelle Risiko zu bewerten .
Repräsentationsverzerrungen treten auf, wenn bestimmte Gruppen in den Trainingsdaten unterrepräsentiert sind. Ein Beispiel: Eine Studie zu Gesichtserkennung zeigte, dass eine häufig genutzte Evaluierungsdatenbank fast 80 % hellhäutige Gesichter enthielt. Das führte zu deutlich höheren Fehlerquoten bei Menschen mit dunklerer Hautfarbe. Ähnliche Probleme können in der Versicherungsbranche auftreten, wenn Bevölkerungsgruppen systematisch falsch eingeschätzt werden.
Ein weiteres Problem stellen Proxy-Attribute dar. Damit kann eine KI sensible Merkmale wie ethnische Herkunft oder sozioökonomischen Status indirekt aus scheinbar neutralen Angaben wie Postleitzahl, Einkommen oder Bildung ableiten .
Doch nicht nur die Daten, sondern auch die Entwicklungsentscheidungen haben großen Einfluss auf die Neutralität von KI-Systemen.
Designfehler in Algorithmen
Voreingenommenheit kann bereits während der Entwicklung eines Algorithmus entstehen – oft durch unbeabsichtigte Annahmen oder fehlende Fairness-Prüfungen. Sowohl Underfitting (zu wenige relevante Variablen) als auch Overfitting (zu viele Variablen) können dazu führen, dass ein Modell reale Zusammenhänge nicht korrekt abbildet.
„Eine (schwache) KI lernt, ohne die von ihr erkannten Muster eigenständig zu hinterfragen."
– Springer Nature
Ein prominentes Beispiel ist das KI-gestützte Recruiting-Tool von Amazon, das 2018 eingestellt wurde. Es benachteiligte systematisch Frauen, da es mit historischen Bewerbungsdaten trainiert wurde, die überwiegend von Männern stammten. Der Algorithmus bewertete Lebensläufe negativ, die Begriffe wie „women's" enthielten, und bevorzugte Formulierungen, die eher mit Männern assoziiert wurden .
Ein weiteres Problem sind aggregierte Vorhersageziele, die oft die Mehrheitsgruppe priorisieren. Ohne explizite Berücksichtigung von Fairness in der Zielfunktion können solche Algorithmen diskriminierende Muster entwickeln, um ihre Ziele effizient zu erreichen.
Diese Designfehler zeigen, wie wichtig eine kontinuierliche Überwachung ist, um solche Probleme zu vermeiden.
Fehlende kontinuierliche Überwachung
Selbst nach der Inbetriebnahme eines KI-Systems bleibt Überwachung essenziell, um Verzerrungen zu erkennen und zu korrigieren. Ohne regelmäßige Prüfungen können bestehende Verzerrungen nicht nur bestehen bleiben, sondern sich sogar verschärfen. KI-Systeme passen sich oft an neue Daten an oder verändern interne Gewichtungen, was zusätzliche Voreingenommenheiten mit sich bringen kann.
Das Problem der Skalierbarkeit von Voreingenommenheit macht KI-Diskriminierung besonders gravierend. Jede Entscheidung – ob bei Prämienberechnungen oder Schadensabrechnungen – trägt diese Verzerrung weiter. Wenn ein System täglich Tausende solcher Entscheidungen trifft, können die Auswirkungen enorm sein.
Ein weiteres Risiko ist der Automationsbias: Menschen vertrauen automatisierten Systemen oft unkritisch und hinterfragen deren Ergebnisse selten. Ohne klare Mechanismen zur Überprüfung und Korrektur von KI-Entscheidungen können diskriminierende Muster langfristig bestehen bleiben. Die EU-KI-Verordnung verpflichtet daher Betreiber von Hochrisiko-Systemen zu einer lückenlosen Überwachung über den gesamten Lebenszyklus. Bei Verstößen drohen Geldbußen von bis zu 15 Millionen Euro oder 3 % des weltweiten Jahresumsatzes.
sbb-itb-d35113a
So lässt sich Diskriminierung in Versicherungs-APIs verhindern
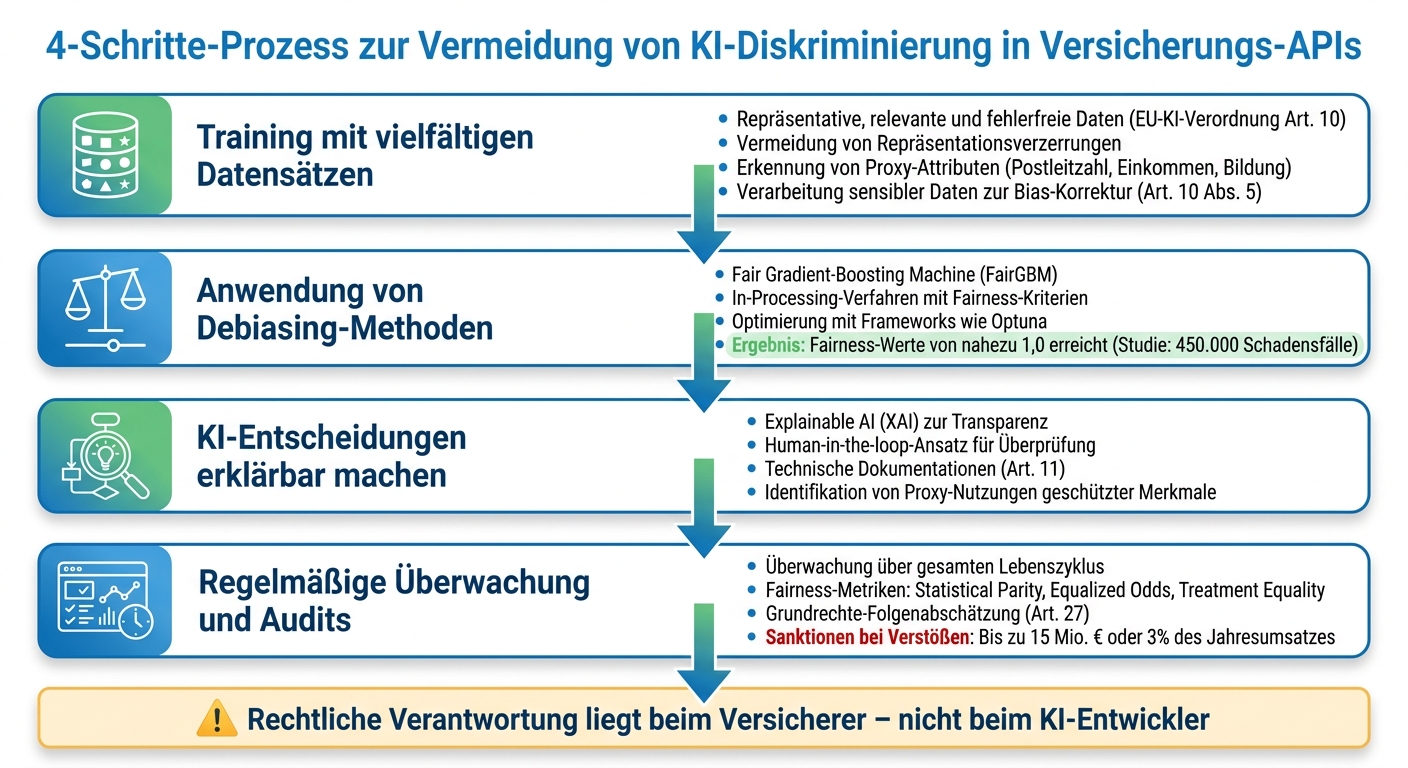
4-Stufen-Prozess zur Vermeidung von KI-Diskriminierung in Versicherungs-APIs
Nachdem die Ursachen für Voreingenommenheit identifiziert sind, stellt sich die Frage: Wie können Versicherungen sicherstellen, dass ihre KI-Systeme fair und transparent arbeiten? Hier sind einige zentrale Ansätze.
Training mit vielfältigen Datensätzen
Die EU-KI-Verordnung (Art. 10) verpflichtet Betreiber von Hochrisiko-Systemen, ihre Daten sorgfältig zu verwalten. Das bedeutet: Trainingsdaten müssen repräsentativ, relevant und fehlerfrei sein. Nur so lassen sich Repräsentationsverzerrungen vermeiden. Es reicht jedoch nicht aus, sensible Merkmale wie Geschlecht oder Herkunft einfach zu entfernen. Denn sogenannte Proxy-Attribute – wie Postleitzahl, Einkommen oder Bildungsgrad – können diese Informationen indirekt weitergeben.
Die Verordnung erlaubt daher in Art. 10 Abs. 5 die Verarbeitung sensibler Daten, wenn dies notwendig ist, um Verzerrungen zu erkennen und zu korrigieren. Das Ziel: ein gerechteres Modell, das alle Bevölkerungsgruppen berücksichtigt.
Anwendung von Debiasing-Methoden
In-Processing-Verfahren gehen einen Schritt weiter, indem sie Fairness-Kriterien direkt in den Trainingsprozess integrieren. Ein Beispiel dafür ist die Fair Gradient-Boosting Machine (FairGBM). Diese Methode stellt sicher, dass verschiedene demografische Gruppen gleiche Chancen erhalten – etwa durch identische True-Positive-Raten.
Eine Studie von Springer Nature aus dem November 2025 untersuchte einen österreichischen Versicherer mit 450.000 Schadensfällen. Das ursprüngliche Modell diskriminierte weibliche Versicherungsnehmer systematisch, da sie häufiger falsch-negative Vorhersagen bei „explosiven Schadensfällen" (Schäden über 100.000 €) erhielten. Mit FairGBM konnten die Forscher nahezu perfekte Fairness-Werte (1,0) erreichen.
Zur Optimierung der Modellparameter kommen Frameworks wie Optuna zum Einsatz. Diese Tools helfen, die Leistung zu maximieren und gleichzeitig Fairness-Schwellenwerte einzuhalten. Sinkt beispielsweise die TPR-Ratio unter 0,5, wird das Modell automatisch angepasst.
KI-Entscheidungen erklärbar machen
Transparenz ist entscheidend, um versteckte Diskriminierung aufzudecken. Die EU-KI-Verordnung verlangt, dass Hochrisiko-Systeme so gestaltet sind, dass Nutzer die Ergebnisse verstehen und sinnvoll nutzen können.
Explainable AI (XAI) spielt hierbei eine zentrale Rolle. Sie zeigt auf, welche Faktoren eine Entscheidung beeinflusst haben, und hilft, mögliche Proxy-Nutzungen geschützter Merkmale zu identifizieren. Ein Human-in-the-loop-Ansatz sorgt dafür, dass menschliche Experten automatisierte Entscheidungen überprüfen und gegebenenfalls korrigieren. Das ist besonders wichtig bei sensiblen Prozessen wie der Risikoprüfung oder Schadensabwicklung.
„HRAIS müssen so gestaltet sein, dass eine wirksame menschliche Aufsicht jederzeit möglich ist. Die eingesetzten Kontrollmechanismen sollen sicherstellen, dass die Betreiber sich der Gefahr eines übermäßigen Vertrauens in die automatisierten Ergebnisse bewusst sind."
– Timo Peters, Europa-Union Hamburg e.V.
Technische Dokumentationen (Art. 11) erleichtern Audits und machen Designentscheidungen nachvollziehbar. Diese Transparenz ist die Basis für regelmäßige Kontrollen, um Fairness sicherzustellen.
Regelmäßige Überwachung und Audits
KI-Systeme sollten über ihren gesamten Lebenszyklus hinweg überwacht werden – von der Entwicklung über den Betrieb bis zur Stilllegung. Regelmäßige Audits setzen auf spezifische Fairness-Metriken, wie:
- Statistical Parity (gleiche Akzeptanzraten)
- Equalized Odds (gleiche True/False-Positive-Raten)
- Treatment Equality
Bei stark unausgewogenen Datensätzen – wie den „explosiven Schadensfällen", die nur 0,01 % aller Fälle ausmachen – können normalisierte Verhältnisse genutzt werden, um Diskrepanzen sichtbar zu machen, die Standardmetriken übersehen.
Die Verordnung verlangt zudem, dass Anbieter Marktüberwachungsbehörden Zugang zu Dokumentationen, Datensätzen und in bestimmten Fällen auch zum Quellcode gewähren. Bei Verstößen drohen Bußgelder von bis zu 15 Millionen Euro oder 3 % des weltweiten Jahresumsatzes.
Vor der Inbetriebnahme sollte eine Grundrechte-Folgenabschätzung (Art. 27) durchgeführt werden. Diese identifiziert potenzielle negative Auswirkungen auf geschützte Gruppen und bildet die Grundlage für fairere KI-Systeme.
Umsetzung fairer KI in Versicherungs-APIs
Wie wird faire KI in Versicherungs-APIs tatsächlich umgesetzt? Versicherer stehen vor der Herausforderung, rechtliche Anforderungen in technische Lösungen zu überführen. Dabei gibt es eine Implementierungslücke: Die EU-KI-Verordnung untersagt Diskriminierung klar, liefert jedoch keine präzisen mathematischen Definitionen für Fairness. Versicherungen müssen daher eigenständig Strategien entwickeln, um ethische Standards in ihre API-Infrastruktur einzubinden. Im Folgenden wird beleuchtet, wie spezifische Versicherungsprozesse, digitale Bewertungsplattformen und regulatorische Kooperationen dazu beitragen können.
Anpassung der KI an spezifische Versicherungsaufgaben
Um Diskriminierung zu vermeiden, müssen KI-Modelle gezielt auf die Anforderungen einzelner Versicherungsprozesse abgestimmt werden. Ein Beispiel ist die Schadensvorhersage. Hierbei sollen Modelle sogenannte „explosive Schadensfälle" – wie Reserveerhöhungen über 100.000 € oder Verzehnfachungen innerhalb eines Monats – zuverlässig erkennen. Eine Studie von Springer Nature aus November 2025 untersuchte 450.000 Schadensfälle eines österreichischen Versicherers und zeigte, dass das ursprüngliche Light Gradient Boosting Machine (LGBM)-Modell weibliche Versicherte systematisch benachteiligte: Sie erhielten eine um 13 % geringere Wahrscheinlichkeit für eine positive Bewertung. Durch den Einsatz einer Fair Gradient-Boosting Machine (FairGBM) mit optimierten Hyperparametern konnten die Forscher nahezu perfekte Fairness-Werte von 1,0 erzielen.
Da „explosive Schadensfälle" lediglich 0,01 % aller Fälle ausmachen, sind normalisierte Verhältnisse erforderlich, um Diskrepanzen sichtbar zu machen, die von Standardmetriken übersehen werden könnten. Zusätzlich empfiehlt es sich, rückblickende Bewertungen bestehender Systeme durchzuführen, wie es die EU-KI-Verordnung vorsieht.
Einsatz digitaler Begutachtungssysteme
Technologische Anpassungen gehen Hand in Hand mit digitalen Bewertungsplattformen, die faire KI-Prinzipien direkt in den Versicherungsprozess einbetten. Statt auf subjektive menschliche Einschätzungen – die durch persönliche Befindlichkeiten oder kognitive Verzerrungen beeinflusst sein können – zu setzen, liefern objektive Daten eine zuverlässige Grundlage.
Ein Beispiel hierfür ist die KFZ-Schadensbewertung. Systeme wie die von CUBEE erfassen technische Fahrzeugdaten präzise und verarbeiten diese digital. Solche Plattformen ermöglichen die Integration von In-Processing-Techniken wie FairGBM, wodurch Reparaturkosten ausschließlich auf Basis technischer Fakten bewertet werden – ohne Einfluss historischer, möglicherweise voreingenommener menschlicher Gutachten. Zudem erleichtern sie die kontinuierliche Überwachung, die nach der EU-KI-Verordnung verpflichtend ist.
Zusammenarbeit mit Aufsichtsbehörden und Branchenpartnern
Die Kooperation mit Regulierungsbehörden sichert technische Ansätze ab. Faire KI entsteht nicht isoliert. Interdisziplinäre Teams aus Informatikern und Rechtsexperten sind notwendig, um algorithmische Fairness-Metriken mit den Vorgaben des Antidiskriminierungsrechts zu vereinen . In Deutschland überwacht die BaFin (Bundesanstalt für Finanzdienstleistungsaufsicht), dass Versicherer aktive Maßnahmen gegen systematische Prognosefehler ergreifen.
„Die regulatorischen Rahmenbedingungen weisen derzeit einen erheblichen Mangel an quantifizierbaren Metriken oder mathematischen Definitionen von Fairness auf ... Diese Lücke erschwert die Übersetzung rechtlicher Antidiskriminierungsprinzipien in algorithmische Kontexte erheblich."
– Springer Nature
Branchenpartnerschaften können helfen, diese Lücke zu schließen. Reale Datensätze und Fallstudien bieten die Möglichkeit, Techniken zur Bias-Reduktion in Produktionsumgebungen zu testen und zu verbessern. Versicherer sollten jedoch beachten, dass sie selbst – und nicht die KI-Entwickler – rechtlich für Diskriminierung verantwortlich sind, da sie die Vertragsbeziehung zu den Kunden eingehen.
Vorteile fairer KI in Versicherungs-APIs
Die Einführung fairer KI in Versicherungs-APIs bringt zahlreiche Vorteile mit sich – sowohl für Versicherungsunternehmen als auch für ihre Kunden. Neben den ethischen Aspekten zeigen sich auch klare wirtschaftliche Vorteile, die diese Investition lohnenswert machen.
Aufbau von Kundenvertrauen
Transparenz und Neutralität in Entscheidungsprozessen stärken das Vertrauen der Kunden nachhaltig. Algorithmen, die diskriminierende Verzerrungen enthalten, können systematisch ganze Bevölkerungsgruppen von Finanzdienstleistungen ausschließen. Ein Beispiel hierfür ist die englische Kfz-Versicherungsplattform, die durch diskriminierende Praktiken das Vertrauen in die gesamte Branche beeinträchtigt hat. Um solchen Szenarien entgegenzuwirken, setzt die EU auf KI-Systeme, die kontinuierlich überwacht werden. So wird sichergestellt, dass Entscheidungen ausschließlich auf objektiven Risikofaktoren basieren und für Kunden nachvollziehbar bleiben.
Erfüllung regulatorischer Anforderungen
Faire KI hilft Versicherern nicht nur, das Vertrauen ihrer Kunden zu gewinnen, sondern auch, gesetzliche Vorgaben zu erfüllen. Sie ermöglicht es Unternehmen, regulatorische Anforderungen einzuhalten und Sanktionen zu vermeiden. Wie bereits erwähnt, liegt die rechtliche Verantwortung für diskriminierungsfreie KI-Systeme beim Versicherer selbst – und nicht bei den Entwicklern der Algorithmen. Durch die proaktive Einführung fairer Modelle können Versicherer Bußgelder und Haftungsansprüche vermeiden, während sie gleichzeitig den Anforderungen der EU-KI-Verordnung gerecht werden. Dazu gehört auch die rückblickende Überprüfung bestehender Systeme.
Bessere operative Ergebnisse
Unvoreingenommene KI-Modelle bieten nicht nur ethische Vorteile, sondern sorgen auch für präzisere Risikobewertungen und höhere Effizienz. Eine Studie eines österreichischen Versicherers zeigte beispielsweise, dass das ursprüngliche LGBM-Modell weibliche Versicherte benachteiligte. Dies führte dazu, dass Schadensfälle dieser Gruppe häufiger als risikoarm eingestuft wurden, was später unerwartete Kosten durch „explosive Schadensfälle“ über 100.000 € verursachte.
„In realen KI-Systemen, insbesondere im Versicherungssektor, wo Vorhersagegenauigkeit direkt Geschäftsergebnisse und Kundenerfahrungen beeinflusst, ist die Aufrechterhaltung hoher Modellleistung nicht verhandelbar."
– Springer Nature
Mit fairen Modellen wie FairGBM lassen sich Genauigkeit und Gerechtigkeit optimal kombinieren. Diese Modelle identifizieren Hochrisikofälle zuverlässig über alle demografischen Gruppen hinweg. Zudem arbeiten KI-Systeme rund um die Uhr und verarbeiten Informationen schneller als Menschen – ein großer Vorteil, insbesondere bei Schadensspitzen nach Ereignissen wie Unwettern.
Auch Anbieter digitaler Bewertungsprozesse, wie die CUBEE Sachverständigen AG, profitieren von der Umsetzung fairer, transparenter und effizienter Systeme. Solche Technologien verbessern nicht nur die operative Leistung, sondern tragen auch entscheidend zu einer gerechteren Versicherungsbranche bei.
Fazit: Aufbau ethischer KI im Versicherungswesen
Diskriminierung in Versicherungs-APIs zu verhindern, ist nicht länger eine Option – es ist eine rechtliche und wirtschaftliche Pflicht. Versicherer sollten erkennen, dass faire KI-Systeme nicht nur ein moralisches Ziel sind, sondern die Grundlage für langfristigen Erfolg, Kundenzufriedenheit und die Einhaltung regulatorischer Vorgaben. Im Zentrum dieser Bemühungen stehen präzise und verzerrungsfreie Daten.
Der erste Schritt zu einer ethischen KI beginnt mit einer soliden Datenbasis. Versicherer müssen Prozesse entwickeln, um Trainings-, Validierungs- und Testdaten systematisch auf Verzerrungen zu prüfen. Das bloße Entfernen geschützter Merkmale reicht dabei nicht aus, da sogenannte Proxy-Variablen diese Eigenschaften indirekt wiedergeben können .
Technologische Ansätze wie Fair Gradient-Boosting Machines (FairGBM) zeigen, dass Fairness und Genauigkeit miteinander vereinbar sind. Diese Methoden, die Fairness direkt in den Trainingsprozess integrieren, eignen sich besonders für unausgeglichene Datensätze, wie sie in der Versicherungsbranche häufig vorkommen. Gleichzeitig ist eine kontinuierliche Überwachung der Systeme unerlässlich, wie es die EU-KI-Verordnung fordert.
Die Vorteile sind konkret: Versicherer können Bußgelder von bis zu 15 Mio. € oder 3 % des weltweiten Jahresumsatzes vermeiden, ihren Ruf vor Diskriminierungsvorwürfen schützen und ihre Risikobewertungen präzisieren, was ihre operativen Ergebnisse verbessert. Für Kunden bedeutet faire KI mehr finanzielle Chancengleichheit, statt ausgeschlossen zu werden. Und für die Branche insgesamt schafft sie das Vertrauen, das notwendig ist, um automatisierte Systeme zu akzeptieren.
„Faire KI-Systeme im Versicherungswesen müssen diese Dualität navigieren, indem sie Nichtdiskriminierung gewährleisten und gleichzeitig die versicherungsmathematischen Prinzipien wahren, die es Versicherern ermöglichen, nachhaltig zu arbeiten."
– Springer Nature
FAQs
Wie erkenne ich, ob meine Versicherungs-API indirekt über Proxy-Attribute diskriminiert?
Ein genauer Blick auf die Daten und Merkmale Ihrer API ist entscheidend, um potenzielle Diskriminierung zu vermeiden. Proxy-Attribute können dabei besonders problematisch sein. Das sind Merkmale, die zwar nicht direkt geschützte Kategorien wie Geschlecht, Alter oder Ethnie abbilden, aber stark mit diesen korrelieren können. Dadurch könnten sie indirekt diskriminierende Effekte hervorrufen.
Um dies zu verhindern, sollten Sie die Entscheidungen Ihrer API systematisch überprüfen. Nutzen Sie Fairness-Metriken und statistische Analysen, um Ungleichheiten in den Ergebnissen aufzudecken. Regelmäßige Tests und Auswertungen helfen, problematische Muster frühzeitig zu erkennen.
Ein weiterer wichtiger Schritt ist die regelmäßige Überprüfung von Modellen und Daten. Dies kann durch Simulationen mit verschiedenen Datensätzen erfolgen, um sicherzustellen, dass die API auch in unterschiedlichen Szenarien fair bleibt. So können Sie sicherstellen, dass keine unbewussten Verzerrungen in Ihre Modelle einfließen.
Welche Fairness-Metriken sind für Prämien- und Schadenmodelle geeignet?
Fairness-Metriken wie Demografische Parität, Gleichheit der Chancen und Equalized Odds sind nützliche Werkzeuge, um Verzerrungen und Diskriminierung in Prämien- und Schadenmodellen aufzudecken und zu reduzieren. Mit diesen Ansätzen lassen sich diskriminierende Muster in den Daten aufspüren, was dazu beiträgt, gerechtere Ergebnisse zu erreichen.
Wie setze ich Monitoring und Audits für Hochrisiko-KI gemäß EU-KI-Verordnung um?
Um die Anforderungen der EU-KI-Verordnung für Hochrisiko-KI-Systeme zu erfüllen, sind gezielte Maßnahmen notwendig. Eine regelmäßige Überwachung mit Bias-Metriken ist entscheidend, um potenzielle Verzerrungen frühzeitig zu erkennen und zu korrigieren. Ergänzend dazu sollten Audits durchgeführt werden, die nicht nur technische, sondern auch ethische Aspekte berücksichtigen.
Ein klar definierter Prozess zur Überprüfung der KI-Modelle ist unerlässlich. Dieser Prozess sollte flexibel gestaltet sein, damit er kontinuierlich an neue Risiken und Herausforderungen angepasst werden kann. Ziel ist es, mögliche Diskriminierung zu verhindern und die Zuverlässigkeit der Systeme zu gewährleisten.
Standards wie CRISP-DM (Cross Industry Standard Process for Data Mining) können dabei unterstützen. Sie bieten eine strukturierte Vorgehensweise, um Fairness und Transparenz in der Entwicklung und Überwachung von KI-Modellen sicherzustellen. Solche Standards helfen, bewährte Praktiken einzuhalten und Vertrauen in KI-Systeme zu stärken.
Verwandte Blogbeiträge
- KI-gestützte Fahrzeugbewertung: Chancen und Risiken
- Studie: KI in der Fahrzeugschadensbewertung 2025
- Echtzeit-KI in der Fahrzeugbewertung: 3 häufige Probleme und Lösungen
- Wie hilft KI bei der Erkennung von Betrug in KFZ-Gutachten?