
Automatisierte Fahrzeugschadensbewertung spart Zeit und Kosten. Deep-Learning-Modelle wie Faster R-CNN bieten mit 94 % Genauigkeit die besten Ergebnisse bei Bildanalysen, während SVMs bei kleineren Datensätzen oder binären Aufgaben wie „Totalschaden vs. reparabel“ punkten. Strukturierte Daten profitieren von Modellen wie XGBoost oder LightGBM, die komplexe Zusammenhänge effizient verarbeiten.
Überblick der Modelle:
- Faster R-CNN: Höchste Präzision (94 %), ideal für detaillierte Analysen.
- YOLO: Schnell, Echtzeitfähigkeit (90 % Genauigkeit).
- SVM: Effizient bei kleinen Datensätzen, benötigt Vorverarbeitung.
- XGBoost/LightGBM: Stark bei strukturierten Daten wie Reparaturkosten.
Hybride Ansätze kombinieren Bild- und Metadatenmodelle, um sowohl Klassifikation als auch Kostenprognosen zu optimieren. Unternehmen wie die CUBEE Sachverständigen AG setzen solche Systeme ein, um die Bearbeitungszeit von Tagen auf Stunden zu verkürzen und Kosten um 50 % zu senken.
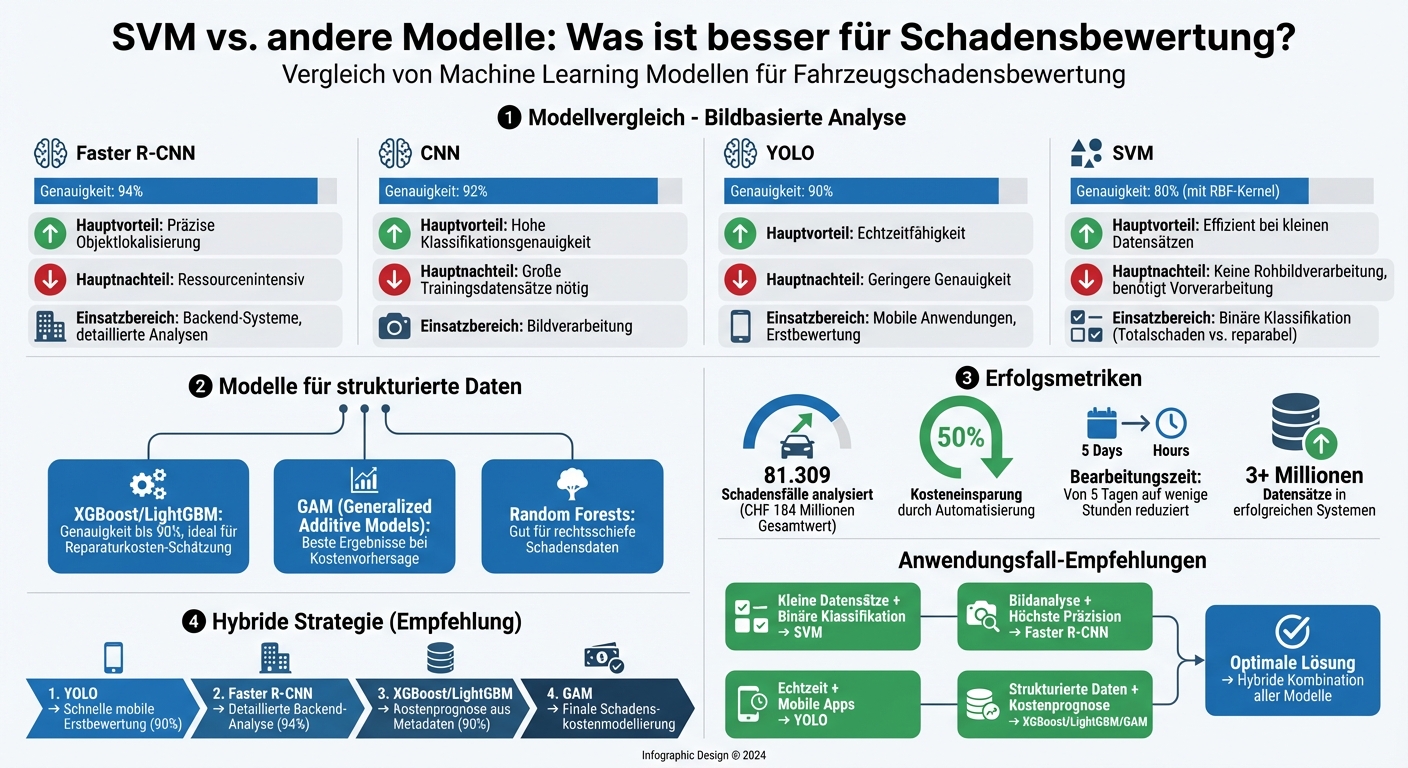
Machine Learning Modelle für Fahrzeugschadensbewertung: Genauigkeit und Einsatzbereiche im Vergleich
Machine-Learning-Modelle zur Schadensbewertung
Die Bewertung von Fahrzeugschäden erfolgt entweder durch bildbasierte Modelle wie Convolutional Neural Networks (CNNs), die Fotos direkt analysieren, oder durch tabellenbasierte Modelle, die strukturierte Daten wie Fahrzeugalter oder Motorleistung nutzen, um Reparaturkosten zu schätzen.
Gängige Modelle zur Schadensklassifikation
Bildbasierte Modelle wie CNNs, YOLO und Faster R-CNN erzielen beeindruckende Ergebnisse. Besonders Faster R-CNN sticht mit einer Genauigkeit von 94 % hervor, selbst bei schwierigen Lichtverhältnissen.
Für strukturierte Daten sind Generalized Linear Models (GLM) und Generalized Additive Models (GAM) die bevorzugten Ansätze, um die Schadensschwere zu modellieren. Tree-basierte Methoden wie Random Forests, XGBoost und LightGBM gehen noch einen Schritt weiter, indem sie komplexe Zusammenhänge zwischen Variablen erfassen, die lineare Modelle oft übersehen. Eine Schweizer Analyse von 81.309 Schadensfällen mit einem Gesamtwert von CHF 184 Millionen zeigte, dass GAM-Modelle die besten Ergebnisse bei der Vorhersage von Schadenskosten lieferten.
Arten von Eingabedaten
Unstrukturierte Bilddaten liefern visuelle Informationen über Schäden wie Dellen, Kratzer oder strukturelle Defekte. Strukturierte Daten umfassen technische Details des Fahrzeugs (PS, Gewicht, Alter), Versicherungsinformationen (Selbstbehalt, Bonus-Malus-Stufe) sowie Angaben zum Fahrzeughalter (Alter, Wohnort). Oft kombinieren Systeme beide Datentypen: Bildmodelle identifizieren die Art des Schadens, während Metadaten-basierte Modelle die Reparaturkosten berechnen. Diese Kombination ermöglicht präzisere Ergebnisse, sei es bei der Klassifikation von Schäden oder der Schätzung der Reparaturkosten.
Ziele des Machine Learning
Maschinelles Lernen verfolgt zwei Hauptziele: Erstens, die exakte Klassifikation von Schadensarten wie Dellen, Kratzern oder strukturellen Schäden. Zweitens, die präzise Schätzung der Reparaturkosten in Euro. Dabei stellt die rechtsschiefe Verteilung der Schadensdaten – mit vielen kleinen und wenigen sehr teuren Schäden – eine besondere Herausforderung dar.
Support Vector Machines: Vorteile und Nachteile
Wie SVMs Schäden klassifizieren
Support Vector Machines (SVMs) arbeiten mit Entscheidungsgrenzen, sogenannten Hyperebenen, die verschiedene Schadenskategorien voneinander trennen. Diese Trennung wird durch die sogenannten Support-Vektoren bestimmt – Datenpunkte, die nahe an der Entscheidungsgrenze liegen und somit den größten Einfluss auf die Klassifikation haben. Mithilfe von Kernel-Funktionen können SVMs auch nicht-lineare Zusammenhänge erkennen, indem sie die Daten in höherdimensionale Räume projizieren. Bei der bildbasierten Schadensbewertung ist eine Vorverarbeitung der Rohbilder notwendig. Hier werden die Bilder in aussagekräftige Merkmale umgewandelt, oft durch den Einsatz vortrainierter Convolutional Neural Networks (CNNs). Ohne diese Vorverarbeitung können SVMs keine Rohbilder direkt verarbeiten. Diese Eigenschaften verdeutlichen, in welchen Bereichen SVMs ihre Stärken ausspielen können.
Wo SVMs gut abschneiden
Die methodischen Eigenschaften von SVMs machen sie besonders geeignet für spezifische Anwendungsfälle. Sie sind ideal für mittelgroße Datensätze, die für Deep-Learning-Modelle oft nicht ausreichen, um effektiv trainiert zu werden. Besonders bei binären Klassifikationsaufgaben, wie der Unterscheidung zwischen „Totalschaden“ und „reparabel“ oder in der Betrugserkennung, zeigen SVMs ihre Stärke. Auch in hochdimensionalen Merkmalsräumen, wie sie beispielsweise in strukturierten Fahrzeugdaten mit vielen Variablen vorkommen, liefern SVMs präzise Ergebnisse – vorausgesetzt, die Merkmale wurden sorgfältig vorbereitet. Ein weiterer Vorteil ist ihre Robustheit gegenüber Ausreißern, da nur die Datenpunkte nahe der Entscheidungsgrenze das Modell wesentlich beeinflussen.
"A simple generalized linear model does not capture interactions of feature components appropriately, whereas the other [machine learning] methods are able to address these interactions." – Alexander Noll, PartnerRe Ltd
Wo SVMs an Grenzen stoßen
Trotz ihrer Stärken stoßen SVMs bei bestimmten Anwendungen an ihre Grenzen. Bei großen Datensätzen können sie langsam und rechenintensiv sein. Im Vergleich zu Deep-Learning-Modellen schneiden sie bei der Verarbeitung von Rohbilddaten deutlich schlechter ab. Während Faster R-CNN beispielsweise eine Genauigkeit von 94 % erreicht, sind SVMs auf vorverarbeitete Features angewiesen. Zudem ist die Optimierung von Hyperparametern, wie der Wahl des richtigen Kernels oder der Regularisierung, komplex und zeitaufwendig. Für tabellarische Versicherungsdaten liefern tree-basierte Ensemble-Methoden wie XGBoost oder LightGBM oft bessere Ergebnisse.
SVM im Vergleich zu anderen Modellen
Nachdem wir die Eigenschaften von Support Vector Machines (SVMs) beleuchtet haben, lohnt sich ein Blick auf den Vergleich mit anderen Modellen. Jedes Modell bringt spezifische Vorteile mit, die je nach Anwendungsfall in der Schadensbewertung unterschiedlich relevant sein können.
SVM vs. Logistische Regression
SVMs und Logistische Regression verfolgen unterschiedliche Ansätze zur Klassifikation. Während SVMs geometrische Methoden nutzen, um die optimale Trennlinie mit maximalem Abstand zu den nächstgelegenen Datenpunkten zu finden, basiert die Logistische Regression auf Wahrscheinlichkeiten, um Entscheidungsgrenzen zu definieren.
Eine Untersuchung mit 23.775 Fahrzeugdatensätzen ergab, dass ein SVM mit RBF-Kernel eine Genauigkeit von 80 % erreichte, während die Logistische Regression bei 69 % lag.
Patricia Bassey von Axum Labs erklärt: „SVM tries to find the 'best' margin (distance between the line and the support vectors) that separates the classes and this reduces the risk of error on the data, while logistic regression does not."
Ein Vorteil der Logistischen Regression ist die Ausgabe kalibrierter Wahrscheinlichkeiten, was bei Unsicherheitsanalysen hilfreich sein kann. SVMs hingegen benötigen zusätzliche Techniken wie Platt Scaling, um ähnliche Funktionalitäten zu bieten. Im nächsten Abschnitt betrachten wir baumbasierte Modelle.
SVM vs. Decision Trees und Random Forests
SVMs arbeiten in hochdimensionalen Räumen, um eine Hyperebene zur Trennung der Klassen zu finden. Im Gegensatz dazu teilen Decision Trees und Random Forests den Eingaberaum durch binäre Regeln auf.
Ein großer Vorteil von Decision Trees ist ihre intuitive Nachvollziehbarkeit. Die Baumstruktur mit klaren Entscheidungsregeln macht es einfacher, die Ergebnisse zu interpretieren. SVMs hingegen operieren in mathematisch komplexen Räumen, was ihre Visualisierung und Interpretation erschwert.
Clem Wang beschreibt den Unterschied so: „SVM's tend to do better when there are lots of input variables... Trees tend to do better when the features are 'lumpy' (e.g. very non-monotonic)".
Random Forests kombinieren mehrere Decision Trees, um Varianz und Überanpassung zu verringern. Eine Analyse von 81.309 Fahrzeugversicherungsansprüchen im Wert von CHF 184 Millionen zeigte, dass Random Forests besonders gut für rechtsschiefe Schadensdaten geeignet sind. Zudem bieten sie die Möglichkeit, automatisch die Wichtigkeit einzelner Merkmale zu berechnen – so können etwa das Fahrzeugalter oder die Aufprallgeschwindigkeit als entscheidende Einflüsse auf die Schadenshöhe identifiziert werden.
SVM vs. Deep Learning (CNNs)
Beim Vergleich von SVMs und Convolutional Neural Networks (CNNs) treten vor allem Unterschiede in der Verarbeitung von Rohbilddaten hervor. CNNs sind speziell für die direkte Bildverarbeitung entwickelt und erzielen bei der Fahrzeugschadenserkennung deutlich höhere Genauigkeiten. SVMs hingegen benötigen eine vorherige Merkmalsextraktion, da sie Rohbilder nicht direkt verarbeiten können.
Deep-Learning-Modelle wie CNNs sind jedoch ressourcenintensiver und erfordern größere Datensätze. SVMs sind dagegen effizienter und eignen sich besser für Anwendungen mit begrenzter Rechenleistung oder kleineren Datensätzen. Für sehr große Datensätze – einige erfolgreiche Systeme verwenden über 3 Millionen Datensätze – entfalten Deep-Learning-Modelle ihre volle Stärke.
CNNs überzeugen zudem durch ihre Robustheit unter variablen Licht- und Umgebungsbedingungen. Automatisierte Deep-Learning-Workflows können die Bearbeitungszeit von durchschnittlich fünf Tagen auf wenige Stunden reduzieren und die Arbeitskosten um bis zu 50 % senken. Für Echtzeitanwendungen bietet YOLO eine besonders schnelle Verarbeitung, auch wenn die Genauigkeit etwas geringer ausfällt.
| Modelltyp | Genauigkeit | Hauptvorteil | Hauptnachteil |
|---|---|---|---|
| Faster R-CNN | 94 % | Präzise Objektlokalisierung | Ressourcenintensiv |
| CNN | 92 % | Hohe Klassifikationsgenauigkeit | Große Trainingsdatensätze nötig |
| YOLO | 90 % | Echtzeitfähigkeit | Geringere Genauigkeit |
| SVM | N/A | Effizient; klare Grenzen | Keine Rohbildverarbeitung |
Einsatz dieser Modelle in der digitalen Schadensbewertung
Beste Modelle für die initiale Klassifikation
Die Wahl des richtigen Modells für die Erstklassifikation hängt stark von den Anforderungen ab. YOLO liefert schnelle Echtzeitergebnisse und erreicht dabei eine Genauigkeit von 90 %, was es ideal für mobile Anwendungen macht. Faster R-CNN hingegen punktet mit einer höheren Genauigkeit von 94 %, benötigt jedoch mehr Rechenleistung und wird daher oft in Backend-Systemen eingesetzt. Bei tabellarischen Daten, wie etwa Fahrzeugalter oder Versicherungsinformationen, erzielen Ensemble-Methoden wie LightGBM und XGBoost Genauigkeiten von bis zu 90 %. Diese Modelle sind ein zentraler Bestandteil digitalisierter Prozesse, wie sie beispielsweise von der CUBEE Sachverständigen AG genutzt werden. Neben der reinen Klassifikation gewinnen auch hybride Ansätze immer mehr an Bedeutung.
Kombination mehrerer Modelle
Ein effektiver Ansatz ist die Kombination verschiedener Modelle, um deren Stärken zu vereinen. So wird häufig die Merkmalsextraktion durch CNNs mit Klassifikatoren wie SVMs oder Gradient-Boosting-Modellen gekoppelt. Ein bemerkenswertes Beispiel stammt von der Southern Methodist University: Im Jahr 2021 entwickelten Forscher einen Workflow, der Mask R-CNN mit statistischen Modellen kombiniert. Mit über 3 Millionen verarbeiteten Datensätzen konnte die Bearbeitungszeit von fünf Tagen auf wenige Stunden reduziert werden, während die Arbeitskosten um 50 % sanken. Solche mehrstufigen Systeme integrieren Bildsegmentierung, Objekterkennung und die Analyse von Metadaten in einem durchgängigen Prozess. Diese hybride Strategie bietet eine effiziente Lösung, die sich nahtlos in digitale Workflows einfügt.
Integration in digitale Workflows
Moderne Systeme zur Schadensbewertung profitieren von vollständig digitalisierten Abläufen. Die CUBEE Sachverständigen AG nutzt solche Workflows, um schnelle und präzise Gutachten zu erstellen – vom Erfassen der Bilder bis hin zum fertigen Bericht. Dabei kommen unterschiedliche Modelle je nach Bedarf zum Einsatz: YOLO eignet sich für die mobile Erstbewertung vor Ort, während Faster R-CNN detaillierte Analysen im Backend übernimmt. Für strukturierte Daten, wie Fahrzeughistorien, werden Ensemble-Modelle bevorzugt.
Um die Transparenz der Modelle zu gewährleisten, werden Techniken wie Grad-CAM oder SHAP eingesetzt. Diese sorgen dafür, dass die Entscheidungsfindung der Modelle nachvollziehbar bleibt – ein entscheidender Faktor in der digitalisierten Gutachtenerstellung. Gleichzeitig ist es unerlässlich, die Modelle regelmäßig nachzuschulen, um mit neuen Fahrzeugmodellen und veränderten Reparaturkosten Schritt zu halten.
Fazit: Das richtige Modell auswählen
Die bisherigen Analysen machen eines klar: Jedes Modell bringt spezifische Vorteile mit, die je nach Einsatzbereich optimal genutzt werden können. Für die bildbasierte Schadenserkennung liefern Deep-Learning-Modelle wie Faster R-CNN (94 % Genauigkeit) und YOLO (90 % Genauigkeit) die besten Ergebnisse. Während Faster R-CNN durch höhere Präzision punktet, überzeugt YOLO mit seiner Geschwindigkeit. Für die Modellierung von Schadenskosten hingegen sind Generalized Additive Models (GAM) sowie XGBoost und LightGBM bei strukturierten Daten besonders geeignet.
SVMs bleiben eine gute Wahl für spezifische Klassifikationsaufgaben, insbesondere bei kleineren Datensätzen oder binären Entscheidungen wie „Totalschaden“ versus „reparabel“. Dennoch zeigen sich Deep-Learning-Ansätze bei der bildbasierten Schadenserkennung als deutlich leistungsstärker. Die CUBEE Sachverständigen AG setzt auf eine differenzierte Strategie: YOLO für schnelle mobile Erstbewertungen, Faster R-CNN für detaillierte Analysen und Ensemble-Modelle zur Verarbeitung von Metadaten.
Die beste Lösung erfordert einen Ausgleich zwischen Genauigkeit, Geschwindigkeit und Transparenz. Tools wie Grad-CAM helfen dabei, die Entscheidungen der Modelle nachvollziehbar zu machen – ein entscheidender Faktor für Versicherer und Kunden. Automatisierte Prozesse reduzieren die Arbeitskosten um etwa 50 % und verkürzen die Bearbeitungszeit von mehreren Tagen auf nur wenige Stunden.
Letztlich zeigt sich, dass eine hybride Modellstrategie klare Vorteile bietet: CNNs für die Bilderkennung, GAMs für die Kostenprognose und YOLO für schnelle Ersteinschätzungen. Um die langfristige Leistungsfähigkeit des Systems zu gewährleisten, ist ein regelmäßiges Nachtraining mit aktuellen Fahrzeugdaten und Reparaturkosten unverzichtbar.
FAQs
Warum ist die Kombination aus Bild- und Metadatenmodellen bei der Fahrzeug-Schadensbewertung so effektiv?
Die Verbindung von Bild- und Metadatenmodellen sorgt bei der Bewertung von Fahrzeugschäden für genauere und schnellere Ergebnisse. KI-Modelle, die auf Bildern basieren, analysieren visuelle Details wie Kratzer, Dellen oder Lackschäden. Ergänzend dazu liefern Metadaten – etwa Fahrzeugtyp, Baujahr oder Kilometerstand – wichtige Kontextinformationen. Das bedeutet, dass auch Schäden erkannt werden können, die auf Fotos allein schwer sichtbar sind, beispielsweise durch schlechte Beleuchtung oder verdeckte Bereiche.
Diese Kombination hat auch einen großen Einfluss auf die Kostenkalkulation. Metadaten ermöglichen es, Faktoren wie Ersatzteilpreise, Reparaturzeiten und den aktuellen Fahrzeugwert einzubeziehen. Dadurch entsteht nicht nur eine präzise Schadensanalyse, sondern auch eine realistische Schätzung der Reparaturkosten in Euro (€). Der gesamte Prozess wird dadurch effizienter, was sowohl Versicherern als auch Kunden klare und nachvollziehbare Ergebnisse liefert.
Wann sind Support Vector Machines (SVMs) besonders nützlich für die Schadensbewertung?
SVMs (Support Vector Machines) sind besonders nützlich, wenn Daten hochdimensional sind, aber nur eine begrenzte Menge an Trainingsbeispielen vorliegt. Sie erzielen zuverlässige Vorhersagen, indem sie den Abstand zwischen den Klassen maximieren, was eine effektive Generalisierung ermöglicht.
Ein weiterer Vorteil von SVMs liegt in ihrer Fähigkeit, sowohl bei klar trennbaren Klassen als auch bei nicht-linearen Zusammenhängen zu überzeugen. Mithilfe von Kernel-Funktionen können sie komplexe Muster erfassen, indem sie die Daten in höherdimensionale Räume abbilden – und das, ohne dass das Modell selbst explizit nicht-linear sein muss.
Gerade für die Fahrzeug-Schadensbewertung spielen diese Stärken eine zentrale Rolle. Beispielsweise können SVMs Bildmerkmale wie Kanten und Texturen analysieren, um Schadensarten präzise zu klassifizieren – selbst dann, wenn nur eine begrenzte Menge an Daten vorliegt.
Wie wirkt sich die Datensatzgröße auf die Wahl des Machine-Learning-Modells für die Schadensbewertung aus?
Die Größe des Datensatzes spielt eine zentrale Rolle, wenn es darum geht, das passende Machine-Learning-Modell für die Fahrzeug-Schadensbewertung auszuwählen. Support-Vector-Machines (SVM) sind ideal für kleinere bis mittlere, hochdimensionale Datensätze. Der Grund: SVMs nutzen lediglich eine Teilmenge der Daten – die sogenannten Support-Vektoren. Dadurch liefern sie auch bei begrenztem Datenvolumen verlässliche Ergebnisse. Allerdings stoßen sie bei sehr großen Datensätzen an ihre Grenzen, da die Rechen- und Speicheranforderungen stark ansteigen und ihre Effizienz beeinträchtigen.
Für große Datensätze bieten sich skalierbare Modelle wie Random Forest, Gradient Boosting oder Deep Learning an. Diese Algorithmen sind darauf ausgelegt, umfangreiche Bild- und Sensordaten effizient zu verarbeiten. Sie punkten zudem mit einer höheren Geschwindigkeit bei der Analyse, was sie besonders für große Datenmengen attraktiv macht.
Bei der CUBEE Sachverständigen AG wird das Machine-Learning-Modell stets an das verfügbare Trainingsvolumen angepasst. SVMs kommen dann zum Einsatz, wenn kleinere, hochdimensionale Bilddatensätze vorliegen. Für größere Datenarchive setzt man hingegen auf skalierbare Ansätze, um eine optimale Balance zwischen Genauigkeit und Verarbeitungsgeschwindigkeit zu erreichen.
Verwandte Blogbeiträge
- Wie KI und Computer Vision Fahrzeugschäden erkennen
- So funktioniert KI-gestützte Schadensbewertung
- Hybride KI-Modelle: Beispiele aus der Praxis
- Studie: KI in der Fahrzeugschadensbewertung 2025