
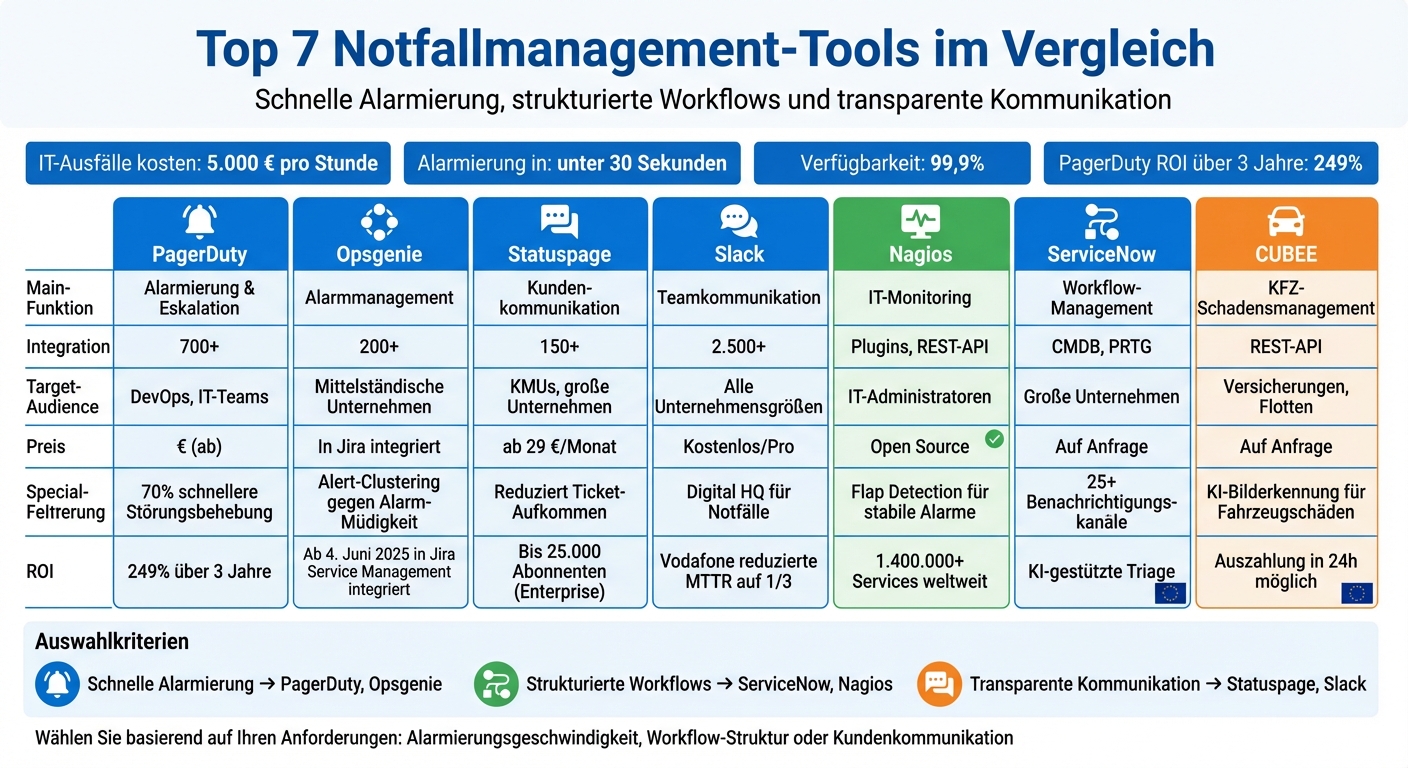
Wenn ein Service ausfällt, ist schnelle Reaktion entscheidend. IT-Ausfälle kosten Unternehmen durchschnittlich 5.000 € pro Stunde und beeinträchtigen Finanzen, Kundenvertrauen und Compliance. Manuelle Prozesse wie Excel-Tabellen oder Anrufketten verlängern die Wiederherstellungszeit (MTTR) oft erheblich. Moderne Tools können hier Abhilfe schaffen: Sie alarmieren in unter 30 Sekunden, senken die MTTR drastisch und erreichen eine Verfügbarkeit von 99,9 %.
Hier sind die Top 7 Lösungen, die Ihnen helfen, Ausfallzeiten zu minimieren:
- PagerDuty: Schnelle Alarmierung, KI-gestützte Filterung, 700+ Integrationen.
- Opsgenie: Zentralisiertes Alarmmanagement, bald integriert in Jira Service Management.
- Statuspage: Transparente Kommunikation mit Kunden über Servicezustände.
- Slack: Kommunikationsplattform für Incident-Management mit 2.500 Integrationen.
- Nagios: Open-Source-Monitoring für IT-Infrastrukturen mit Plugins und APIs.
- ServiceNow: Cloudbasierte Plattform für Enterprise-Service-Management.
- CUBEE Sachverständigen AG: Digitale Prozesse für schnelle Schadensbearbeitung.
Schnellvergleich:
| Tool | Hauptfunktion | Integrationen | Zielgruppe | Preis (ab) |
|---|---|---|---|---|
| PagerDuty | Alarmierung, Eskalation | 700+ | DevOps, IT-Teams | € |
| Opsgenie | Alarmmanagement | 200+ | Mittelständische Unternehmen | In Jira integriert |
| Statuspage | Kundenkommunikation | 150+ | KMUs, große Unternehmen | 29 €/Monat |
| Slack | Teamkommunikation | 2.500+ | Alle Unternehmensgrößen | Kostenlos/Pro |
| Nagios | IT-Monitoring | Plugins, REST-API | IT-Administratoren | Open Source |
| ServiceNow | Workflow-Management | CMDB, PRTG | Große Unternehmen | Auf Anfrage |
| CUBEE | KFZ-Schadensmanagement | REST-API | Versicherungen, Flotten | Auf Anfrage |
Wählen Sie basierend auf Ihren Anforderungen: schnelle Alarmierung, strukturierte Workflows oder transparente Kommunikation. Effektives Notfallmanagement spart Zeit, Geld und schützt Ihr Unternehmen vor größeren Schäden.
Vergleich der 7 besten Notfallmanagement-Tools für IT-Serviceausfälle
1. PagerDuty
PagerDuty ist eine Plattform für Incident Management, die schnelle Reaktionen auf kritische Ereignisse ermöglicht. Sie informiert das Bereitschaftsteam über SMS, Push-Benachrichtigungen, Telefon und E-Mail, damit keine wichtige Meldung unbeachtet bleibt.
Benachrichtigungs- und Alarmierungsfunktionen
Mit automatischen Eskalationsketten sorgt PagerDuty dafür, dass Alarme, die nicht rechtzeitig bestätigt werden, direkt an die nächste zuständige Person weitergeleitet werden. Die Plattform nutzt KI-gestützte Funktionen, um zusammenhängende Ereignisse zu gruppieren und Fehlalarme herauszufiltern. So können Teams ihre Aufmerksamkeit auf wirklich dringende Probleme lenken. Diese gezielte Filterung verbessert auch die nahtlose Integration in bestehende Systeme. Unternehmen, die PagerDuty einsetzen, beheben Störungen bis zu 70 % schneller.
Integration in bestehende Systeme
PagerDuty bietet über 700 native Integrationen und lässt sich problemlos in nahezu jede IT-Infrastruktur einbinden. Besonders praktisch: Die Integration mit Tools wie Slack und Microsoft Teams ermöglicht es, Vorfälle direkt im Chat zu bearbeiten, zu bestätigen und zu lösen .
Joan Martinez, Engineering Manager bei Glovo, beschreibt es so: „PagerDuty hat es uns wirklich ermöglicht, DevOps-Praktiken einzuführen und unsere bestehenden Prozesse zu verbessern, anstatt alles auszutauschen".
Diese nahtlose Einbindung schafft die Grundlage für eine flexible Skalierung, wie im nächsten Abschnitt näher beschrieben wird.
Skalierbarkeit und Wirtschaftlichkeit
Die Plattform passt sich dem Wachstum von Unternehmen an. Standardisierte Service-Konfigurationen unterstützen Teams dabei, bewährte Prozesse effizient umzusetzen. Der finanzielle Nutzen ist beachtlich: Der ROI über drei Jahre liegt bei 249 %, und die durchschnittliche Amortisationszeit beträgt nur 12 Monate. Unternehmen sparen durch kürzere Ausfallzeiten jährlich im Durchschnitt 3,48 Mio. €, und DevOps-Teams arbeiten 27 % produktiver .
2. Opsgenie
Opsgenie ist eine Plattform für zentrales Alarmmanagement, die Benachrichtigungen aus verschiedenen Überwachungs- und Logging-Tools an einem Ort bündelt. Entwickelt von Atlassian, zeichnet sich die Lösung durch ihre Fähigkeit aus, Alarme intelligent zu filtern und zu gruppieren. Wichtig: Ab dem 4. Juni 2025 wird Opsgenie nicht mehr als eigenständiges Produkt verfügbar sein. Seine Funktionen werden in Jira Service Management und Compass integriert. Die folgenden Abschnitte beleuchten die wichtigsten Benachrichtigungs- und Integrationsfunktionen.
Benachrichtigungs- und Alarmierungsfunktionen
Opsgenie ermöglicht die Zustellung von Alarmen über verschiedene Kanäle und nutzt eine Alert-Clustering-Funktion, um ähnliche Alarme zu einem Vorfall zusammenzuführen. Dadurch wird die sogenannte Alarm-Müdigkeit reduziert. Zusätzlich können eingehende Anrufe direkt an den zuständigen Ingenieur weitergeleitet werden, was die Reaktionszeit erheblich verkürzt.
Integration in bestehende Systeme
Die Plattform bietet nahtlose Integration mit über 200 Anwendungen, einschließlich führender Monitoring-Tools und Kommunikationsdienste. Beispielsweise erlaubt die Verbindung mit Elastic, Alarme basierend auf spezifischen Überwachungsregeln automatisch zu erstellen oder zu schließen. Darüber hinaus unterstützt Opsgenie Terraform-Provider, wodurch Bereitschaftspläne und Eskalationsrichtlinien effizient als Code verwaltet werden können.
Echtzeit-Überwachung und Reporting
Die Incident Timeline dokumentiert automatisch alle Aktivitäten im Incident Command Center, wie Chat-Verläufe oder Änderungen im Alarmstatus. Diese Funktion bietet eine wertvolle Grundlage für Post-Mortem-Analysen. Außerdem aktualisiert Opsgenie Statusseiten in Echtzeit und informiert interne sowie externe Stakeholder über den Fortschritt. Das reduziert die manuelle Kommunikationslast während Störungen erheblich. Diese Funktionen bilden die Basis für effektive und skalierbare Alarmstrategien.
Skalierbarkeit für verschiedene Unternehmensgrößen
Dank leistungsstarker Reporting-Funktionen eignet sich Opsgenie auch für wachsende Unternehmen. Alarme können spezifischen Diensten und Teams zugeordnet werden, sodass nur relevante Mitarbeiter benachrichtigt werden. Dies ist besonders in großen Netzwerken von Vorteil. Nach der Migration auf Jira Service Management oder Compass bietet Atlassian eine 120-tägige Parallelphase an, bevor die ursprüngliche Instanz deaktiviert wird. Unternehmen sollten die bereitgestellten Migrationswerkzeuge nutzen, um rechtzeitig umzusteigen.
3. Statuspage
Statuspage von Atlassian bietet eine klare und transparente Möglichkeit, Kunden und Mitarbeiter während Serviceausfällen auf dem Laufenden zu halten. Anders als reine Monitoring-Tools konzentriert sich Statuspage auf proaktive Kommunikation über verschiedene Kanäle wie E-Mail, SMS, Slack und Microsoft Teams.
Benachrichtigungs- und Alarmierungsfunktionen
Eines der Highlights von Statuspage ist die komponentenbasierte Kommunikation. Unternehmen können den Status einzelner Servicekomponenten anzeigen, sodass Nutzer genau wissen, welche Bereiche betroffen sind. Über 150 Drittanbieter-Integrationen – darunter Stripe, Mailgun und Shopify – erweitern die Funktionalität. Mit proaktiven Benachrichtigungen hilft Statuspage, das Ticket-Aufkommen während Vorfällen zu reduzieren. Vorlagen für Vorfallmeldungen ermöglichen es, schnell und professionell zu reagieren, was gerade in stressigen Situationen entscheidend ist. Diese Kommunikationsstrategie ergänzt die Alarmierungs- und Automatisierungsfunktionen, die ebenfalls integriert sind.
Integration in bestehende Systeme
Statuspage lässt sich problemlos in bestehende IT-Umgebungen integrieren, insbesondere in das Atlassian-Ökosystem. Die Verbindung mit Jira Service Management erleichtert die Verwaltung von Wartungsfenstern. REST-APIs und Webhooks (verfügbar ab 99 €/Monat im Startup-Tarif) bieten Unternehmen die Möglichkeit, Automatisierungen individuell anzupassen. Ebenso hilft die Anbindung an Help-Desk-Systeme dabei, doppelte Support-Anfragen zu vermeiden, indem Nutzer automatisch über den aktuellen Status informiert werden.
Skalierbarkeit für verschiedene Unternehmensgrößen
Statuspage bietet flexible Preismodelle, die sich an die Bedürfnisse unterschiedlicher Teams anpassen. Für kleine Teams gibt es ein kostenloses Modell mit 100 Abonnenten und 2 Teammitgliedern. Größere Unternehmen können das Enterprise-Paket für 1.499 €/Monat nutzen, das bis zu 25.000 Abonnenten, 50 Teammitglieder, rollenbasierte Zugriffskontrolle sowie vollständige Anpassung von CSS/HTML/JS umfasst. Für interne Zwecke stehen Private Pages zur Verfügung, die ab 79 €/Monat erhältlich sind und Funktionen wie IP-Allowlisting und SSO bieten. Mit der Uptime Showcase-Funktion können Unternehmen historische Verfügbarkeitsdaten nutzen, um potenziellen Kunden ihre Zuverlässigkeit zu demonstrieren.
4. Slack
Slack hat sich von einer einfachen Kommunikationsplattform zu einem zentralen Steuerungssystem für Notfälle entwickelt. Es dient als "Digital HQ", in dem Teams, Daten und Tools zusammengeführt werden, um Serviceausfälle schnell zu erkennen und zu beheben. Kritische Alarme aus Monitoring-Tools wie PagerDuty, Opsgenie oder Datadog werden automatisch in spezielle Slack-Kanäle geleitet – so bleiben wichtige Meldungen nicht in überfüllten E-Mail-Postfächern stecken.
Benachrichtigungs- und Alarmierungsfunktionen
Eine der größten Stärken von Slack ist die automatisierte Weiterleitung von Alarmen und die strukturierte Kommunikation bei Vorfällen. Teams erstellen spezielle Kanäle, wie #inc- oder #help-, um Störungsmeldungen gezielt zu bearbeiten und Reaktionsteams zu aktivieren, ohne die gesamte Organisation zu stören. Mit dem No-Code Workflow Builder können standardisierte Incident-Formulare erstellt werden, die zeitkritische Informationen automatisch an die relevanten Kanäle senden. Ein cleverer Tipp: Nutzen Sie benutzerdefinierte Emojis, um wichtige Meilensteine oder Updates in der Incident-Timeline hervorzuheben – das macht es einfacher, in langen Diskussionen den Überblick zu behalten.
"Slack is the only platform that has been able to deliver information in real time and parsed out to who needs it." – Chris Mastroianni, Special Operations Group Sergeant, Hartford Police Department
Diese automatisierten Workflows sorgen dafür, dass Slack nahtlos in bestehende IT-Systeme integriert werden kann.
Integration in bestehende Systeme
Slack bietet über 2.500 Integrationen, die eine einfache Verbindung mit Ihrer bestehenden IT-Infrastruktur ermöglichen. Mit der Service Cloud for Slack-Integration wird beispielsweise automatisches "Swarming" möglich: Experten werden sofort in einen Kanal eingeladen, wenn komplexe Probleme auftreten. Für externe Bedrohungen lassen sich auch RSS-Feeds von Behörden wie dem BSI direkt in Slack-Kanäle einbinden. Die zeitgestempelten Kanalverläufe eignen sich zudem hervorragend als objektive Audit-Trails für Post-Mortem-Analysen.
Diese vielseitigen Integrationsmöglichkeiten machen Slack für Unternehmen jeder Größe attraktiv.
Skalierbarkeit für verschiedene Unternehmensgrößen
Slack ist flexibel genug, um sowohl kleine Teams als auch große Organisationen zu unterstützen. Mit Slack Connect können bis zu 250 verschiedene Organisationen in einem einzigen Kanal zusammenarbeiten – ideal für die Koordination zwischen Partnern und Dienstleistern. Ein Beispiel: Vodafone konnte durch die Nutzung von Slack die mittlere Lösungszeit (MTTR) auf ein Drittel reduzieren. Für gemeinnützige Organisationen bietet Slack zudem kostenlose oder stark vergünstigte Tarife an. Enterprise-Kunden profitieren von erweiterten Sicherheitsfunktionen wie Enterprise Key Management (EKM) und Audit-Logs, die selbst strengste Compliance-Anforderungen erfüllen.
5. Nagios
Nagios ist eine bewährte Open-Source-Software, die als zuverlässiges Überwachungssystem für IT-Infrastrukturen dient. Sie prüft kontinuierlich den Zustand von Hosts und Services und stuft diese in die Kategorien OK, Warning, Critical oder Unknown ein. Besonders interessant ist die sogenannte Flap Detection: Sie analysiert die letzten 21 Überprüfungen, um unnötige Alarme zu vermeiden, bis sich der Status stabilisiert hat.
Echtzeit-Monitoring und Reporting
Ein praktisches Beispiel für den Einsatz von Nagios liefert die amedes-Gruppe, ein medizinischer Dienstleister mit 3.500 Mitarbeitern. Im April 2018 führten sie eine Nagios-basierte Lösung namens SNAG-View ein, um 800 Hosts und 2.500 Services an 60 Standorten zu überwachen. Mithilfe von "Dynamic Maps" konnten sie den Status ihrer IT-Systeme und WAN-Verbindungen zentral visualisieren. Heiko Schönfeld, IT-Administrator bei amedes, erläutert:
"Im Vergleich zur vorherigen Lösung ist die Darstellung des Status der einzelnen Standorte übersichtlicher und Probleme können schneller identifiziert werden."
Integration in bestehende Systeme
Nagios lässt sich dank einer REST-API problemlos in andere Systeme wie Zammad integrieren. So können automatisch Tickets erstellt, Aktivitäten protokolliert und Tickets nach Behebung eines Problems geschlossen werden. Darüber hinaus ermöglicht die große Auswahl an Community-Plugins die Überwachung nahezu aller relevanten Komponenten. Ein weiteres Beispiel: Die Perschmann Business Services GmbH nutzt Nagios seit 2011, um 230 Hosts und 1.425 Services zu überwachen. Um die Überwachung effizient auf die Standorte in Nürnberg und Berlin zu verteilen, wurden zwei Gearman-Workers implementiert, die ein verteiltes Monitoring ermöglichen.
Skalierbarkeit für Unternehmen jeder Größe
Nagios-basierte Frameworks wie openITCOCKPIT sind weltweit in über 20 Ländern im Einsatz und verwalten mehr als 1.400.000 Services. Für größere IT-Umgebungen bietet Nagios verteilte Monitoring-Architekturen, die mithilfe von Gearman-Workers die Last auf mehrere Standorte verteilen. Moderne Frontends erweitern die Funktionalität zusätzlich, indem sie mobile Apps mit Push-Benachrichtigungen bereitstellen. So können Administratoren Alarme auch unterwegs empfangen und schnell darauf reagieren. Diese flexible Architektur macht Nagios zu einer leistungsstarken Lösung für Unternehmen jeder Größe, von kleinen Teams bis hin zu global verteilten Infrastrukturen. Die Kombination aus Skalierbarkeit und mobiler Unterstützung unterstreicht den Wert von Nagios in der heutigen IT-Landschaft.
6. ServiceNow
ServiceNow ist eine cloudbasierte Plattform für Enterprise-Service-Management, die speziell auf die Bedürfnisse mittelständischer und großer Unternehmen zugeschnitten ist. Dank ihres modularen Aufbaus mit IT- und Kunden-Workflows können Unternehmen gezielt starten und die Plattform flexibel erweitern. Als zentrale Informationsquelle eliminiert ServiceNow Datensilos und verbindet Vorfälle, Probleme und Änderungsanfragen nahtlos miteinander . Dies erleichtert nicht nur den Übergang zu fortschrittlichen Notfallmanagement-Funktionen, sondern verbessert auch die Effizienz.
Incident-Benachrichtigung und Alarmierung
ServiceNow unterstützt Omni-Channel-Benachrichtigungen über mehr als 25 Kanäle, darunter Self-Service-Portale, Chatbots, E-Mail, Telefon und mobile Apps. Dies sorgt für eine reibungslose Eskalation von Vorfällen . Automatisierte On-Call-Zeitpläne stellen sicher, dass Vorfälle rund um die Uhr nach festgelegten Kriterien eskaliert werden. Mithilfe KI-gestützter Triage werden Incidents automatisch den richtigen Teams zugewiesen, was die manuelle Bearbeitungszeit erheblich verkürzt.
"What I loved about ServiceNow from the beginning is its ability to connect the dots. You really get out of it what you put in. The more processes you have in ServiceNow, the more those dots are connected." – Travis West, Business Resiliency Manager bei Canadian Tire
Neben der schnellen Alarmierung verbessert ServiceNow durch umfassende Systemintegration die gesamte Incident-Bewältigung und sorgt für eine optimierte Reaktion.
Integration in bestehende Systeme und Workflows
ServiceNow bietet Echtzeit-Integration in die Configuration Management Database (CMDB) und unterstützt spezialisierte Konnektoren wie PRTG, um eine vollständige Transparenz über IT-Komponenten zu gewährleisten. Zertifizierte Integrationen mit Krisenmanagement-Tools wie Everbridge und der Einsatz moderner KI-Modelle treiben die Prozessautomatisierung voran . Mit dem benutzerfreundlichen Flow Designer können Unternehmen Prozesse per Drag-and-Drop automatisieren – ganz ohne Programmierkenntnisse.
Skalierbarkeit für Unternehmen unterschiedlicher Größen
ServiceNow kombiniert Incident-Management mit umfassender Systemintegration und wird so zu einer zentralen Plattform für die Notfallkoordination. Ein Beispiel: Die Investitionsbank des Landes Brandenburg (ILB) konnte durch den Einsatz von ServiceNow-Tools wie ITSM, ITOM, SPM und IRM die Automatisierung steigern, Medienbrüche reduzieren und regulatorische Anforderungen der BaFin erfüllen. Gleichzeitig nutzte ein DAX-30-Unternehmen die HR Service Delivery von ServiceNow, um Transaktionszeiten zu verkürzen und den manuellen E-Mail-Aufwand durch ein globales Self-Service-Portal erheblich zu reduzieren.
"Now Assist is a game changer, in the user experience and in saving time and money for the business." – Mark Blyth, Head of Business Solutions bei Mears Group
7. CUBEE Sachverständigen AG
Die CUBEE Sachverständigen AG bietet ein europaweites Netzwerk für digitalisierte KFZ-Gutachten an, das auf einem innovativen Container-System basiert. Mithilfe einer benutzerfreundlichen Web-Anwendung können Fahrzeugschäden direkt am Unfallort erfasst werden. Eine integrierte KI analysiert die eingereichten Bilder, erkennt automatisch beschädigte Fahrzeugteile sowie Schadensarten wie Dellen, Kratzer oder Risse und überprüft dabei sowohl die Bildqualität als auch die Plausibilität der Angaben. Für komplexere Schäden steht eine Live-Video-Inspektion zur Verfügung, bei der ein Experte den Nutzer in Echtzeit begleitet und sofort einen rechtssicheren digitalen Bericht erstellt. Automatisierte Prozesse setzen anschließend Folgeaktionen in Gang – sei es die Weiterleitung an eine Werkstatt, interne Eskalationen oder die Reparaturfreigabe. Dank der REST-API-Integration werden Informationen nahtlos in ERP-, CRM- oder Schadensmanagementsysteme übertragen, wodurch Medienbrüche vermieden werden. Diese Technologie ermöglicht ein schnelles und effizientes Management in Notfallsituationen.
Im Vergleich zu herkömmlichen Versicherungsprozessen, die oft zwei bis sechs Wochen dauern, reduzieren die digitalisierten Abläufe die Bearbeitungszeit auf etwa zwei bis vier Wochen. In optimalen Fällen kann die Auszahlung sogar innerhalb von 24 Stunden erfolgen.
Für Flottenbetreiber bietet die regelmäßige digitale Zustandserfassung – etwa im Vierteljahresrhythmus – eine vollständige Fahrzeughistorie. Diese sorgt dafür, dass mögliche Probleme frühzeitig erkannt werden. Eine lückenlose Dokumentation hilft außerdem, Streitigkeiten bei Leasingrückgaben oder Flottenübergaben zu vermeiden. Bei Fahrzeugbeschlagnahmen oder Bergungen ermöglicht die sofortige digitale Erfassung nach der Übernahme eine schnelle und präzise Bewertung des Fahrzeugzustands.
Feature Comparison
Im Bereich Notfallmanagement spielen Schnelligkeit und eine präzise Integration eine entscheidende Rolle. Die Unterschiede zwischen den verfügbaren Tools liegen vor allem in der Reaktionszeit, der Integrationsfähigkeit und der Struktur der Workflows.
Alarmierungsplattformen wie PagerDuty und Opsgenie sind auf schnelle Reaktionszeiten ausgelegt – oft unter 30 Sekunden. Sie bieten zudem Multi-Channel-Benachrichtigungen über SMS, Push-Nachrichten und Anrufe, um sicherzustellen, dass kritische Alarme sofort wahrgenommen werden.
ITSM-Plattformen wie ServiceNow hingegen setzen auf strukturierte Workflows, umfassende Ticketing-Systeme und eine detaillierte Compliance-Dokumentation. Diese Eigenschaften machen sie besonders geeignet für Unternehmen mit strengen Governance-Vorgaben. Auch bei den Integrationen gibt es klare Unterschiede: Moderne Alarmierungstools lassen sich problemlos mit Monitoring-Systemen wie Prometheus oder Datadog verbinden. ITSM-Lösungen punkten hingegen durch nahtlose Anbindungen an CMDBs und Change-Management-Prozesse. Zusätzlich spielen Collaboration-Tools wie Slack eine Schlüsselrolle, indem sie als zentrale „War Rooms“ fungieren. Hier können Teams Alarme direkt über Bots bestätigen, ohne die Plattform wechseln zu müssen. Spezialisierte Anbieter wie SIGNL4 bieten darüber hinaus mehr als 200 verifizierte Integrationen mit Drittanbietern. Diese Unterschiede beeinflussen die Wahl des passenden Tools je nach individuellen Anforderungen eines Unternehmens.
Neben den technischen Merkmalen gibt es auch deutliche Unterschiede bei den Preismodellen. So startet Statuspage bei 29 € pro Monat, während Hyperping für vergleichbare Funktionen 74 € pro Monat verlangt. Einige Anbieter setzen zudem auf Versicherungsmodelle, um ihre Services zu kalkulieren.
Für mittelständische Unternehmen ist ein weiterer Aspekt besonders relevant: IT-Ausfälle verursachen durchschnittlich Kosten von über 5.000 € pro Stunde. Tools mit Funktionen wie RBAC (Role-Based Access Control) und SSO (Single Sign-On), die oft in Enterprise-Tarifen enthalten sind, sind bei der Koordination über Regionen hinweg unverzichtbar. Unternehmen, die auf DSGVO-Konformität angewiesen sind, sollten Lösungen mit EU-Hosting bevorzugen, wie etwa Hyperping oder Nica Software. In kritischen Situationen ist Compliance ein Muss.
Diese Vergleichspunkte helfen Unternehmen dabei, die richtige strategische Entscheidung bei der Auswahl ihres Notfallmanagement-Tools zu treffen.
"ITSM-Plattformen sind nicht unbedingt optimal für Echtzeit-Incident-Response." – ilert Buyer's Guide
Fazit
Wählen Sie Ihr Notfallmanagement-Tool basierend auf den spezifischen Anforderungen Ihres Unternehmens: Managed Service Provider profitieren von Funktionen wie Multi-Tenancy und kundenspezifischen Statusseiten, während Startups und DevOps-Teams auf tief integrierte CI/CD-Pipelines und Infrastructure-as-Code setzen. Mittelständische Unternehmen bevorzugen oft pragmatische und kostenbewusste Lösungen, die unkompliziert in der Anwendung sind.
Analysieren Sie Ihren Incident-Flow genau. Erfassen Sie die Zeiten für Triage, Diagnose und Behebung, um mögliche Engpässe zu identifizieren. Überlegen Sie, ob Probleme wie manuelle Schichtplanung, verpasste Alarme oder fehlende Skalierbarkeit die Hauptursache sind. Eine reibungslose Integration mit Monitoring-Systemen wie Prometheus oder Datadog ist ebenfalls entscheidend.
Setzen Sie auf Anbieter, die Provider-Level-Redundanz bieten. Das bedeutet, dass mehrere Telekommunikationspartner eingebunden werden, um selbst bei einem Carrier-Ausfall eine zuverlässige Alarmierung per SMS oder Sprachanruf sicherzustellen. So minimieren Sie Ausfallzeiten effektiv.
Beginnen Sie mit risikoarmen Szenarien wie Cache-Löschungen oder Deployment-Rollbacks, bevor Sie Automatisierung oder KI-Tools vollständig implementieren. Für Unternehmen in Europa ist ein DSGVO-konformes Hosting innerhalb der EU unverzichtbar. Die vorgestellten Tools decken ein breites Spektrum ab – von schneller Alarmierung über strukturierte Workflows bis hin zu transparenter Kommunikation mit Kunden. Diese gezielten Maßnahmen maximieren den Nutzen der Tools und helfen, Ihre Prozesse optimal zu ergänzen.
FAQs
Wie finde ich das richtige Notfallmanagement-Tool für mein Unternehmen?
Der erste Schritt bei der Wahl eines Notfallmanagement-Tools ist, die spezifischen Anforderungen Ihres Unternehmens genau zu definieren. Überlegen Sie, welche Arten von Störungen abgedeckt werden sollen – von IT-Ausfällen bis hin zu physischen Ereignissen wie Bränden. Berücksichtigen Sie dabei auch relevante Standards und regulatorische Vorgaben, die für Ihr Unternehmen gelten. Tools, die beispielsweise Methoden wie ISO 22301 oder den BSI-Standard unterstützen, können hier besonders nützlich sein.
Ein weiterer wichtiger Punkt ist die Überprüfung der Funktionen des Tools. Fragen Sie sich:
- Werden Vorlagen für Notfallpläne bereitgestellt?
- Gibt es automatisierte Alarmierungsfunktionen?
- Kann das Tool Daten aus bestehenden Systemen integrieren?
Auch Aspekte wie Benutzerfreundlichkeit, Skalierbarkeit und die Kostenstruktur sollten in Ihre Entscheidung einfließen. Zertifizierte Tools mit einem verlässlichen Support-Netzwerk machen die Implementierung einfacher und reduzieren mögliche Risiken.
Ein gründlicher Vergleich Ihrer Anforderungen mit den Funktionen der verfügbaren Tools ist entscheidend. So finden Sie eine Lösung, die nicht nur Ausfallzeiten minimiert, sondern auch die Abläufe in Ihrem Unternehmen effizienter gestaltet.
Welche Vorteile bringt die Integration von Alarmierungstools in bestehende Systeme mit sich?
Die Einbindung von Alarmierungstools in bestehende IT- und Geschäftssysteme bringt Unternehmen klare Vorteile. Vorfälle lassen sich in Sekundenschnelle melden – sei es durch automatisierte Auslöser oder einen einfachen Knopfdruck. Das spart nicht nur wertvolle Zeit, sondern liefert auch Echtzeit-Einblicke in die Verfügbarkeit des Personals. So können die richtigen Ansprechpartner gezielt kontaktiert werden, basierend auf Schichtplänen, Standorten oder individuellen Einstellungen.
Darüber hinaus verbessern automatisierte Eskalations- und Feedback-Prozesse die Reaktionszeiten und optimieren Abläufe kontinuierlich. Die Kommunikation wird ebenfalls erleichtert, da bestehende Kanäle wie E-Mail, SMS oder Push-Benachrichtigungen nahtlos integriert werden können. Das Ergebnis? Kürzere Ausfallzeiten, eine höhere Serviceverfügbarkeit und eine gestärkte betriebliche Widerstandsfähigkeit.
Wie helfen Notfallmanagement-Tools dabei, Serviceausfälle schneller zu beheben?
Notfallmanagement-Tools helfen dabei, Serviceausfälle schneller zu beheben, indem sie Abläufe automatisieren und eine klare Übersicht in Echtzeit bieten. Störungen werden zentral gesammelt, priorisiert und automatisch den zuständigen Teams zugewiesen. Das minimiert manuelle Fehler und verkürzt die Reaktionszeiten erheblich.
KI-gestützte Analysen liefern Vorschläge für geeignete Lösungsansätze, während vordefinierte Workflows sowie Vorlagen ein schnelles und gezieltes Handeln ermöglichen. Automatische Benachrichtigungen und eine koordinierte Kommunikation stellen sicher, dass alle Beteiligten informiert sind und effizient reagieren können.
Darüber hinaus sorgt die fortlaufende Dokumentation und Analyse von Vorfällen dafür, dass Abläufe verbessert werden können. Unternehmen gewinnen wertvolle Erkenntnisse aus vergangenen Ereignissen und können ihre Prozesse so anpassen, um die Wiederherstellungszeit langfristig weiter zu verkürzen.
Verwandte Blogbeiträge
- Wie funktioniert ein Incident-Response-Plan?
- Best Practices für Drittanbieter-Datenüberwachung
- Wie digitale Tools die Kommunikation bei Gutachten verbessern
- Top 3 Tools für Wettbewerber-Preisanalysen im Vergleich