
Kreuzvalidierung ist eine Methode, um die Leistung von KI-gestützten Schadensmodellen zu bewerten. Besonders bei Schadensmodellen hilft sie, Überanpassung zu vermeiden und die Generalisierungsfähigkeit zu prüfen. Dabei wird der Datensatz in Trainings- und Testabschnitte aufgeteilt, um sicherzustellen, dass das Modell nicht nur spezifische Datenpunkte „auswendig lernt“, sondern Muster erkennt, die auf neue Daten anwendbar sind.
Wichtige Punkte:
- Warum wichtig? Verhindert Überanpassung und verbessert die Zuverlässigkeit bei neuen Daten.
- Herausforderungen bei Schadensmodellen: Unausgewogene Daten (z. B. 95 % unbeschädigt, 5 % beschädigt) und Datenkorrelationen (z. B. mehrere Bilder desselben Schadens).
- Häufige Methoden:
- K-Fold-Kreuzvalidierung: Datensatz wird in k Teile aufgeteilt, z. B. 80 % Training, 20 % Test.
- Stratifizierte K-Fold: Behält Klassenverteilung in allen Folds bei.
- Hold-Out-Methode: Einfache Einteilung in Trainings- und Testset (z. B. 80:20).
- Leave-One-Out (LOOCV): Jeder Datenpunkt wird einzeln getestet, ideal für kleine Datensätze.
Die Wahl der Methode hängt von der Datensatzgröße, Klassenverteilung und Rechenkapazität ab. Schadensmodelle profitieren besonders von stratifizierten und gruppenbasierten Ansätzen, um Verzerrungen zu vermeiden und präzise Ergebnisse zu liefern.
Grundlagen der Kreuzvalidierung
Kreuzvalidierung basiert auf einem klaren Prinzip: Der Datensatz wird in Trainingsdaten und Validierungsdaten aufgeteilt. Die Trainingsdaten dienen dazu, die Modellparameter zu optimieren, während die Validierungsdaten verwendet werden, um die Leistung des Modells auf bislang ungesehenen Daten zu bewerten. Dieses Verfahren simuliert den realen Einsatz, bei dem das Modell historische Muster nutzt, um Schäden mithilfe spezialisierter KI-Tools für die KFZ-Schadensbewertung zuverlässig zu klassifizieren.
Das Ziel ist, dass das Modell nicht einfach nur auswendiglernt, sondern allgemeingültige Muster erkennt, die auf neue Daten anwendbar sind. Ein häufig verwendeter Ansatz ist die Hold-Out-Methode. Hierbei wird der Datensatz in ein Trainings- und ein Testset unterteilt. Die Modellgenauigkeit wird dann ausschließlich auf dem Testset berechnet, was eine objektive Bewertung des sogenannten „Out-of-Sample-Fehlers“ ermöglicht. Besonders bei Schadensmodellen spielt die stratifizierte Validierung eine entscheidende Rolle, wie im Folgenden erläutert wird.
Warum Schadensmodelle Kreuzvalidierung benötigen
Schadensmodelle stehen vor spezifischen Herausforderungen, die den Einsatz von Kreuzvalidierung notwendig machen. Ein typisches Problem sind unausgewogene Datensätze. In der Schadenserkennung besteht häufig ein starkes Ungleichgewicht, beispielsweise 95 % unbeschädigte und nur 5 % beschädigte Teile. Ohne stratifizierte Kreuzvalidierung könnte es passieren, dass ein Fold keine beschädigten Beispiele enthält, was zu einer verzerrten Bewertung führt.
Ein weiteres Problem ist die Korrelation innerhalb der Daten. Mehrere Bilder desselben Schadens oder Sensormessungen aus einem einzigen Ereignis können zu „Information Leakage“ führen. Dadurch erscheint das Modell leistungsfähiger, als es tatsächlich ist. Gruppen-Kreuzvalidierung kann hier Abhilfe schaffen, indem sie sicherstellt, dass Daten aus unterschiedlichen Materialchargen oder Standorten getrennt berücksichtigt werden. Dies ermöglicht eine realistischere Bewertung der Generalisierungsfähigkeit über verschiedene Domänen hinweg.
Leistungskennzahlen für Schadensmodelle
Während der Kreuzvalidierung wird die Leistung eines Schadensmodells anhand verschiedener Metriken gemessen. Accuracy (Genauigkeit) gibt an, wie viele Fälle korrekt klassifiziert wurden. Precision (Präzision) zeigt, wie viele der als „beschädigt“ klassifizierten Teile tatsächlich Schäden aufweisen – eine wichtige Metrik, um Fehlalarme zu minimieren. Recall misst, wie viele der tatsächlich beschädigten Teile erkannt werden. Der F1-Score kombiniert Precision und Recall, um eine ausgewogene Bewertung zu ermöglichen.
Diese Metriken werden für jeden Fold separat berechnet und anschließend gemittelt, um eine robuste Gesamtbewertung zu erhalten. Sie bilden die Grundlage für die Analyse und den Vergleich verschiedener Kreuzvalidierungsansätze.
sbb-itb-d35113a
Kreuzvalidierungsmethoden für die Schadenserkennung
Aufbauend auf den Grundlagen der Kreuzvalidierung gibt es verschiedene Ansätze, die speziell für die Schadenserkennung genutzt werden können. Die Wahl der geeigneten Methode hängt von der Größe des Datensatzes und der Verteilung der Schadensklassen ab. Dies ist ein entscheidender Schritt in der KFZ-Schadensbewertung, um präzise Ergebnisse zu erzielen. Sie spielt eine zentrale Rolle, um ein Modell zuverlässig zu bewerten und dessen Einsatzfähigkeit in der Praxis sicherzustellen. Im Folgenden werden die gängigsten Methoden beschrieben, zusammen mit ihren jeweiligen Vorzügen und Einschränkungen.
K-Fold-Kreuzvalidierung
Bei der K-Fold-Kreuzvalidierung wird der Datensatz in k gleich große Teile aufgeteilt. Das Modell wird dann k‑mal trainiert, wobei jedes Mal ein anderer Fold als Validierungsset dient, während die restlichen k‑1 Folds für das Training verwendet werden. Die endgültige Bewertung des Modells ergibt sich aus dem Durchschnitt der Ergebnisse aller k Durchläufe.
Typischerweise liegt der Wert für k zwischen 5 und 10, abhängig von der Größe des Datensatzes. Diese Methode ist besonders nützlich für kleine oder unausgewogene Datensätze, da jede Beobachtung sowohl im Trainings- als auch im Validierungsprozess berücksichtigt wird. Bei einem 5-Fold-Ansatz beispielsweise entfallen etwa 80 % der Daten auf das Training und 20 % auf die Validierung.
Eine Variante dieser Methode, die stratifizierte K-Fold-Kreuzvalidierung, ist besonders wichtig bei Schadensdatensätzen. Sie sorgt dafür, dass die Verteilung der Schadensklassen in allen Folds erhalten bleibt . Dies hilft, die typischen Probleme unausgewogener Datensätze zu bewältigen und gewährleistet eine robuste Modellbewertung.
Hold-Out-Methode
Die Hold-Out-Methode ist eine einfachere Alternative. Hier wird der Datensatz einmalig in ein Trainingsset und ein Validierungsset aufgeteilt, meist im Verhältnis 80:20 oder 70:30.
Der größte Vorteil dieser Methode liegt in ihrer Rechengeschwindigkeit, da das Modell nur einmal trainiert werden muss. Das macht sie besonders geeignet für sehr große Datensätze, bei denen eine einzige Aufteilung bereits ausreichend aussagekräftig ist. Diese Methode eignet sich gut für schnelle Validierungen in produktiven Umgebungen, bietet jedoch keine so umfassende Bewertung wie die K-Fold-Kreuzvalidierung.
Leave-One-Out-Kreuzvalidierung (LOOCV)
LOOCV ist eine spezielle Form der K-Fold-Kreuzvalidierung, bei der die Anzahl der Folds der Gesamtzahl der Datenpunkte (N) entspricht. Das bedeutet, dass jeder Datenpunkt einmal als Validierungsset verwendet wird, während das Modell auf den verbleibenden N‑1 Datenpunkten trainiert wird.
Dieser Ansatz maximiert die Nutzung der verfügbaren Daten und ist besonders hilfreich bei sehr kleinen Datensätzen oder bei seltenen Schadenstypen, wo jede Beobachtung zählt. Allerdings ist der Rechenaufwand enorm, da das Modell N‑mal trainiert werden muss. Zudem ist bei LOOCV keine Stratifizierung möglich, was bei unausgewogenen Datensätzen ein Nachteil sein kann. Daher wird diese Methode vor allem in spezialisierten Szenarien eingesetzt, bei denen die maximale Datennutzung im Vordergrund steht.
So implementieren Sie Kreuzvalidierung für Schadensmodelle
Python-Setup für die Kreuzvalidierung
Die Kreuzvalidierung für Fahrzeugschadensmodelle wird häufig mit digitalen Tools für Gutachter und Python und der scikit-learn-Bibliothek umgesetzt. Diese stellt hilfreiche Funktionen wie cross_val_score für die Bewertung mit einer einzelnen Metrik und cross_validate für die gleichzeitige Analyse mehrerer Metriken (z. B. Präzision und Recall) bereit.
Bei Modellen mit unausgewogenen Klassen – etwa wenn strukturelle Schäden seltener auftreten als Lackschäden – ist StratifiedKFold eine gute Wahl, da es die Klassenverteilung in jedem Fold beibehält. Falls Ihr Datensatz mehrere Bilder desselben Fahrzeugs enthält, sollten Sie GroupKFold oder StratifiedGroupKFold verwenden. Diese Methoden verhindern Datenlecks, indem sichergestellt wird, dass alle Bilder eines Fahrzeugs in einem einzigen Fold bleiben.
Mit make_pipeline können Sie Vorverarbeitungsschritte direkt in die Validierung einbinden. Dies verhindert, dass Informationen aus dem Test-Fold in den Trainingsprozess einfließen. Wenn Sie KFold verwenden, sollten Sie den Parameter shuffle=True sowie einen festen random_state setzen, um Verzerrungen zu vermeiden. Nach der Implementierung können Sie die Ergebnisse analysieren.
Auswertung der Kreuzvalidierungsergebnisse
Der Durchschnittswert aller Folds liefert eine solide Einschätzung der Modellleistung. Die Standardabweichung der Ergebnisse (z. B. mit scores.std()) gibt an, wie stabil das Modell gegenüber unterschiedlichen Datenteilungen ist. Ein hoher Wert deutet darauf hin, dass das Modell empfindlich auf Variationen in den Daten reagiert.
Um Overfitting zu erkennen, sollten Sie die Trainings- und Validierungsergebnisse vergleichen. Aktivieren Sie return_train_score=True in cross_validate. Ein großer Unterschied zwischen den Trainings- und Validierungswerten (z. B. 89 % gegenüber 82,4 %) kann ein Hinweis auf Overfitting sein.
Bei der Schadenserkennung reicht die Genauigkeit oft nicht aus, insbesondere bei seltenen Schadenstypen. Daher sollten Sie scoring=['precision_macro', 'recall_macro'] in cross_validate verwenden. So können Sie sowohl die Präzision als auch die Sensitivität des Modells bewerten. Zusätzlich helfen die Angaben zu fit_time und score_time, die Effizienz des Modells zu verbessern.
Vergleich der Kreuzvalidierungsmethoden
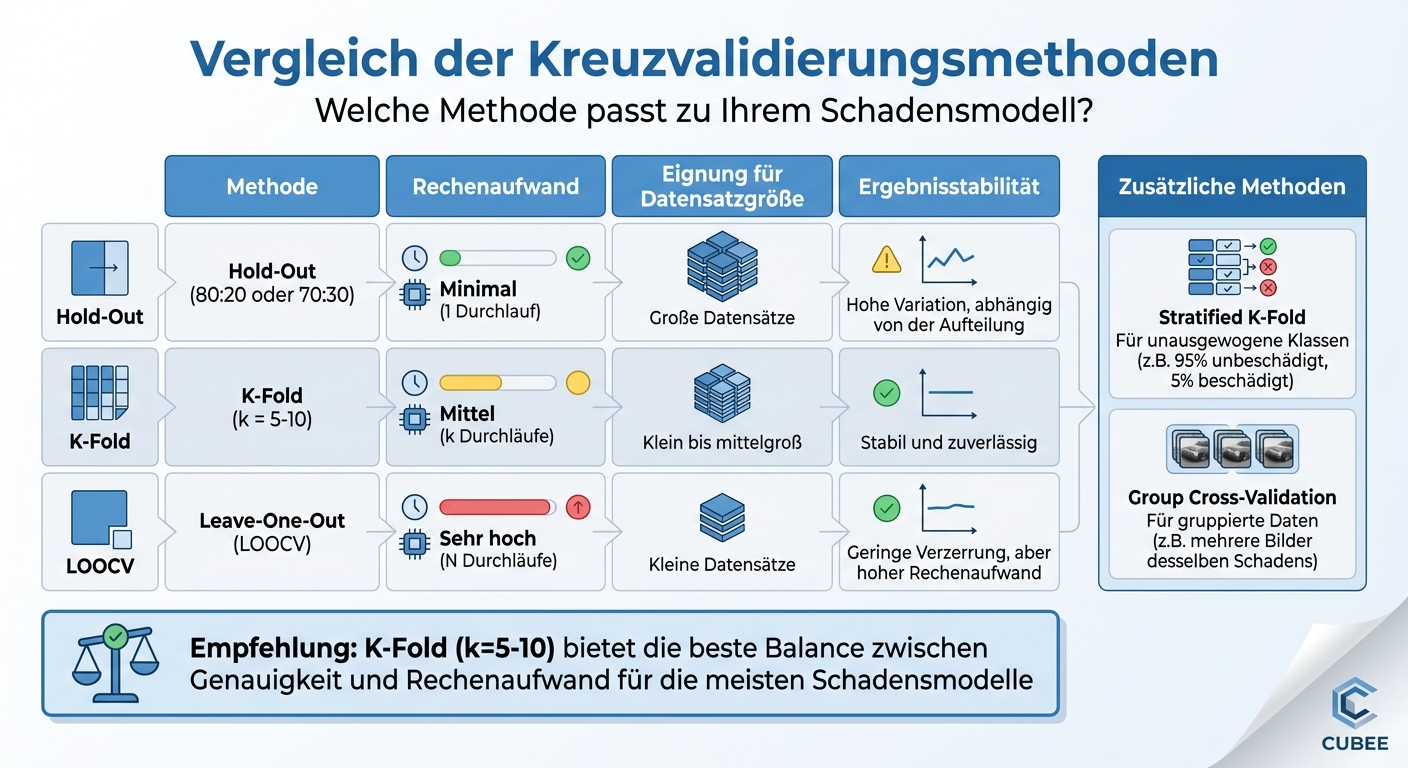
Vergleich der Kreuzvalidierungsmethoden für Schadensmodelle
Im Folgenden finden Sie eine übersichtliche Gegenüberstellung der vorgestellten Kreuzvalidierungsmethoden.
Jede Methode hat ihre eigenen Vorzüge und Schwächen, die bei der Arbeit mit Schadensmodellen berücksichtigt werden sollten. Die Hold-out-Methode ist die einfachste und schnellste Option. Dabei wird der Datensatz einmalig, meist standardisiert, in Trainings- und Validierungsdaten aufgeteilt. Diese Methode eignet sich besonders für größere Datensätze, da bei kleineren Datenmengen das Risiko besteht, dass die Aufteilung unausgewogen ist – etwa wenn beschädigte und unbeschädigte Beispiele ungleich verteilt sind.
Die K-Fold-Kreuzvalidierung teilt die Daten in k gleich große Teile und trainiert das Modell k-mal, wobei in jedem Durchgang ein anderer Teil als Validierungsdaten verwendet wird. In der Praxis wird oft k = 10 gewählt, da dies eine gute Balance zwischen Rechenaufwand und Genauigkeit der Leistungsbewertung bietet. Diese Methode ist robuster als die Hold-out-Methode, da jeder Datenpunkt sowohl für das Training als auch für die Validierung genutzt wird.
Leave-One-Out Cross-Validation (LOOCV) ist ein Sonderfall der K-Fold-Methode, bei dem k der Anzahl der Datenpunkte (N) entspricht. Hier wird jeder Datenpunkt einzeln getestet, was jedoch bei N Durchläufen sehr rechenintensiv ist. Für komplexe KI-Modelle ist LOOCV nur dann sinnvoll, wenn der Datensatz extrem klein ist.
Die folgende Tabelle zeigt die Unterschiede zwischen den Methoden in Bezug auf Rechenaufwand, Eignung und Stabilität der Ergebnisse.
Vergleichstabelle der Kreuzvalidierungsmethoden
| Methode | Rechenaufwand | Eignung für Datensatzgröße | Ergebnisstabilität |
|---|---|---|---|
| Hold-out | Minimal (1 Durchlauf) | Große Datensätze | Hohe Variation, abhängig von der Aufteilung |
| K-Fold | Mittel (k Durchläufe) | Klein bis mittelgroß | Stabil und zuverlässig |
| LOOCV | Sehr hoch (N Durchläufe) | Kleine Datensätze | Geringe Verzerrung, aber hoher Rechenaufwand |
Zusätzlich zu diesen Methoden gibt es stratified und gruppenbasierte Ansätze, die bei unausgewogenen oder gruppierten Datensätzen nützlich sind. Stratified K-Fold sorgt dafür, dass die Klassenverteilung in jedem Fold erhalten bleibt, während Group Cross-Validation Gruppen trennt, um Datenlecks zu vermeiden.
Für Schadensmodelle mit unausgewogenen Klassen – etwa wenn strukturelle Schäden seltener auftreten – ist Stratified K-Fold besonders geeignet. Falls der Datensatz Cluster aufweist (z. B. unterschiedliche Materialtypen), stellt Group Cross-Validation sicher, dass das Modell über verschiedene Domänen hinweg verallgemeinert.
Diese Gegenüberstellung bildet eine solide Grundlage, um im nächsten Schritt die besten Strategien für den Einsatz in Schadensmodellen zu entwickeln.
Best Practices für Kreuzvalidierung bei Schadensmodellen
Die richtige Kreuzvalidierungsmethode auswählen
Die Wahl der passenden Methode hängt von drei zentralen Faktoren ab: der Größe des Datensatzes, der Verteilung der Klassen und der verfügbaren Rechenkapazität.
Bei kleineren Datensätzen empfiehlt sich LOOCV (Leave-One-Out-Cross-Validation) oder K-Fold mit einem hohen k-Wert, um die Daten optimal zu nutzen. Für größere Datensätze sind die Hold-out-Methode oder K-Fold mit niedrigeren k-Werten (in der Regel k = 5 bis 10) sinnvoller, da sie weniger Rechenressourcen erfordern.
Die Verteilung der Klassen ist ebenfalls entscheidend. Wenn das Schadensmodell verschiedene Kategorien wie „beschädigt“ und „unbeschädigt“ oder unterschiedliche Schadensarten unterscheidet, sollte Stratified K-Fold eingesetzt werden. Diese Methode sorgt dafür, dass jeder Fold die gleiche Klassenverteilung wie der Gesamtdatensatz hat. Das ist besonders wichtig bei seltenen Schadensarten, da ohne Stratifizierung einige Folds möglicherweise keine Beispiele dieser Kategorien enthalten würden.
Sind die Daten in Clustern organisiert – beispielsweise nach Fahrzeugmodellen oder Materialtypen – ist Group Cross-Validation unverzichtbar. Sie verhindert, dass das Modell spezifische Cluster lediglich „auswendig lernt“, anstatt eine Generalisierung über verschiedene Gruppen hinweg zu erreichen. Data- & KI-Experte Adriano Ramisarijaona hebt hervor:
"Ein höherer k-Wert führt zu einem weniger verzerrten Modell. Jedoch kann eine zu große Varianz zu einer Überanpassung führen"
Ein weiterer wichtiger Punkt: Standard-Kreuzvalidierung ist für Zeitreihendaten ungeeignet, da das Mischen der Daten zeitliche Abhängigkeiten zerstören würde. Für solche Fälle ist Time-Series Cross-Validation notwendig.
Diese Auswahlkriterien bieten eine solide Grundlage für den gezielten Einsatz der Kreuzvalidierung im KI-System von CUBEE.
Einsatz von Kreuzvalidierung im KI-System von CUBEE
Die oben genannten methodischen Überlegungen werden im KI-System von CUBEE praktisch umgesetzt. Es kombiniert Stratified K-Fold und Group Cross-Validation, um optimale Ergebnisse zu erzielen.
Die CUBEE Sachverständigen AG nutzt Kreuzvalidierung, um die Genauigkeit und Zuverlässigkeit ihrer KI-gestützten Schadenserkennung zu maximieren. Da kleinere Schäden wie Kratzer viel häufiger auftreten als größere strukturelle Schäden, wird Stratified K-Fold eingesetzt, um die unausgewogene Klassenverteilung zwischen „kein Schaden“ und spezifischen Schadensarten auszugleichen.
Zusätzlich sorgt Group Cross-Validation dafür, dass die Algorithmen über verschiedene Fahrzeugmarken, Modelle und Beleuchtungsbedingungen hinweg präzise Ergebnisse liefern. Diese Kombination stellt sicher, dass das Modell auch bei bisher unbekannten Schadensfällen in der Praxis zuverlässige Ergebnisse liefert.
Durch den digitalisierten Prozess von CUBEE werden die Modelle in Echtzeit überwacht und kontinuierlich angepasst. Dank der Parallelisierung der Berechnungen – bei der jeder Fold unabhängig verarbeitet wird – bleibt die Rechenzeit trotz mehrfacher Trainingsdurchläufe überschaubar. Das Resultat: schnelle und präzise KFZ-Gutachten, die auf robusten maschinellen Lernmodellen basieren.
Fazit
Kreuzvalidierung spielt eine zentrale Rolle bei der Entwicklung zuverlässiger Schadensmodelle. Sie sorgt dafür, dass KI-Systeme auch bei unbekannten Schadensfällen präzise Ergebnisse liefern können. Durch die Analyse verschiedener Datenpartitionen bietet diese Methode eine stabile und weniger verzerrte Einschätzung der Modellleistung – deutlich besser als eine einfache Aufteilung in Trainings- und Testdaten.
Die Wahl der passenden Methode hängt von Faktoren wie der Größe des Datensatzes, dem Klassenausgleich und den verfügbaren Rechenressourcen ab. K-Fold-Cross-Validation mit k = 5 oder 10 stellt oft den besten Kompromiss dar. Bei unausgewogenen Datensätzen bietet Stratified K-Fold jedoch klare Vorteile.
Diese Validierungsansätze sind direkt in die digitalen Prozesse von CUBEE integriert. Die CUBEE Sachverständigen AG setzt gezielt erprobte Validierungsstrategien ein, um die Genauigkeit ihrer KI-gestützten Schadenserkennung zu optimieren. Stratified K-Fold gewährleistet dabei, dass die Modelle konsistente Ergebnisse liefern – unabhängig von Fahrzeugtyp, Beleuchtungsbedingungen oder Schadensart. Gleichzeitig sorgt die Möglichkeit zur Parallelisierung der Berechnungen dafür, dass trotz mehrfacher Trainingsläufe kurze Bearbeitungszeiten möglich sind.
Durch diese robuste Validierung kann CUBEE schnelle und präzise KFZ-Gutachten bereitstellen, die auf zuverlässigen maschinellen Lernmodellen basieren und in der Praxis konstant gute Ergebnisse liefern.
FAQs
Wann sollte ich StratifiedGroupKFold statt StratifiedKFold nutzen?
StratifiedGroupKFold ist ideal, wenn Sie eine stratifizierte Kreuzvalidierung benötigen, bei der die Daten in nicht überlappende Gruppen unterteilt sind. Dabei wird jede Gruppe genau einmal einem Test-Set zugeordnet, während gleichzeitig die ursprüngliche Klassenverteilung in den Folds beibehalten wird.
Das ist besonders hilfreich, wenn Ihre Daten in logischen Gruppen organisiert sind, die nicht getrennt werden sollten. Ein typisches Beispiel wäre die Analyse von Fahrzeugschäden, die einem bestimmten Gutachter zugeordnet sind. Hier wäre es problematisch, wenn Daten eines Gutachters sowohl im Trainings- als auch im Test-Set landen würden. StratifiedGroupKFold sorgt dafür, dass dies nicht passiert.
Welche Metrik ist bei seltenen Schäden wichtiger als Accuracy?
Bei seltenen Schäden steht der Recall (Sensitivität) im Vordergrund, da er zeigt, wie effektiv tatsächliche Schäden erkannt werden. Das ist besonders bei seltenen Ereignissen entscheidend. Accuracy kann in solchen Fällen täuschen, da sie auch die korrekte Erkennung von unproblematischen Fällen berücksichtigt und damit das Gesamtbild verzerren kann.
Wie vermeide ich Data Leakage bei mehreren Bildern pro Schadenfall?
Wenn ein Schadenfall mehrere Bilder umfasst, ist es entscheidend, dass alle Bilder desselben Falls in derselben Datenaufteilung bleiben – entweder im Trainings- oder im Testdatensatz. Warum? Weil dies verhindert, dass Informationen zwischen den Datensätzen „durchsickern“, was die Modellbewertung verfälschen könnte.
Ein bewährter Ansatz ist die Verwendung von k-facher Kreuzvalidierung. Dabei sollten Sie sicherstellen, dass alle Bilder eines Schadenfalls stets in derselben Gruppe (Fold) landen. So bleibt die Bewertung des Modells realistisch und bietet eine verlässliche Grundlage für die spätere Anwendung.