
APIs sind das Rückgrat moderner Versicherungssysteme. Sie ermöglichen die Automatisierung von Schadensmeldungen und den Zugriff auf wichtige Daten in Echtzeit. Doch was passiert, wenn eine API ausfällt? Ohne eine durchdachte Fehlerbehandlung drohen Datenverluste, Kundenunzufriedenheit und rechtliche Probleme wie DSGVO-Verstöße.
Die wichtigsten Maßnahmen für Versicherer:
- Fehlerprotokollierung: Erfassen Sie alle Fehler mit Details wie Zeitstempel und Fehlercodes. Sensible Informationen sollten nicht in Protokollen auftauchen.
- Standard-HTTP-Statuscodes: Nutzen Sie passende Codes (z. B. 400 für fehlerhafte Anfragen oder 503 für Serverprobleme), um Fehler klar zu kommunizieren.
- Wiederholungsmechanismen: Automatische Wiederholungen mit Wartezeiten (exponentieller Backoff) helfen bei temporären Fehlern.
- Graceful Degradation: Sorgen Sie dafür, dass kritische Funktionen auch bei Ausfällen verfügbar bleiben, z. B. durch Zwischenspeicherungen.
- Echtzeit-Monitoring: Richten Sie Alarme für Fehlerraten ein, um Probleme frühzeitig zu erkennen und zu beheben.
Warum das wichtig ist: Versicherer können so Ausfallzeiten minimieren, Bearbeitungszeiten verkürzen und sensible Daten schützen. Eine robuste Fehlerbehandlung ist der Schlüssel für reibungslose API-Integrationen und zufriedene Kunden.
Checkliste: Was Versicherer für eine effektive API-Fehlerbehandlung benötigen
Eine solide Fehlerbehandlung basiert auf fünf zentralen Elementen, die zusammen ein belastbares System gewährleisten. Hier sind die wichtigsten Bausteine einer erfolgreichen API-Fehlerbehandlung im Detail.
Vollständige Fehlerprotokollierung
Ein gutes Logging-System erfasst jeden API-Fehler mit genauen Details wie Zeitstempel, Anfrage-Payloads, Header-Informationen und Fehler-Codes. Dabei sollte ein standardisiertes JSON-Format mit klar definierten Feldnamen verwendet werden, insbesondere bei Validierungsfehlern. Fehler sollten nach Typen kategorisiert werden (z. B. Validierung, Authentifizierung, Logik oder Infrastruktur), um Probleme schneller zu identifizieren und Audit-Trails für Compliance-Anforderungen bereitzustellen. Sensible interne Details gehören nicht in die Protokolle.
Standard-HTTP-Statuscodes und Fehlerformate
Die richtige Verwendung von HTTP-Statuscodes erleichtert die Fehlerbehebung enorm. Zum Beispiel:
- 4xx-Codes: Diese signalisieren Client-seitige Probleme, wie 400 für fehlerhafte Anfragen, 401 für fehlende Authentifizierung oder 422 für Validierungsfehler.
- 5xx-Codes: Diese zeigen Server-Probleme an, wie 500 für unbehandelte Ausnahmen oder 503 für Wartungsarbeiten.
Ein häufiger Fehler ist die Rückgabe eines 200-Status mit einer Fehlermeldung im Body – das widerspricht dem HTTP-Standard und behindert automatische Fehlerbehandlungen durch Frameworks. Bei sensiblen Ressourcen ist es zudem ratsam, 404 statt 403 zu verwenden, um keine Daten preiszugeben. Dokumentiere alle möglichen Fehlerantworten mit Tools wie OpenAPI oder Swagger, damit alle Systempartner klare Erwartungen haben.
Wiederholungsmechanismen mit exponentiellem Backoff
Bei temporären Fehlern wie Netzwerkproblemen oder Serverüberlastungen sind automatische Wiederholungsversuche mit exponentiellem Backoff sinnvoll. So erhält der Server Zeit zur Erholung, und die Anzahl fehlgeschlagener Anfragen wird reduziert. Prüfe dabei immer den Retry-After-Header bei 429- oder 503-Antworten, da dieser die empfohlene Wartezeit in Sekunden angibt. Ein zufälliger Verzögerungsanteil (Jitter) hilft, gleichzeitige Wiederholungsanfragen zu vermeiden, die den Server zusätzlich belasten könnten. Für schreibende Anfragen wie POST, PUT oder DELETE sollten Idempotenz-Schlüssel verwendet werden, die typischerweise nach 24 Stunden ablaufen.
Graceful Degradation und Fallback-Optionen
Wenn eine API ausfällt, sollten kritische Funktionen weiterhin verfügbar bleiben. Eine Möglichkeit besteht darin, Workflows in kleinere, durch Bedingungen geschützte Einheiten aufzuteilen. Ist ein Schritt bereits lokal gespeichert, wird er bei erneuten Anfragen übersprungen. Für nicht zeitkritische Aufgaben können Tools wie Sidekiq genutzt werden, die Wiederholungsversuche über längere Zeiträume (bis zu drei Wochen) ermöglichen. In GraphQL-Architekturen lassen sich Teildaten für erfolgreiche Felder zurückgeben, während fehlgeschlagene Bereiche in einem errors-Array dokumentiert werden. So bleibt die Benutzeroberfläche funktionsfähig. Vermeide globale Transaktionen, die externe API-Aufrufe einschließen, da dies die Synchronisation zwischen lokalem und externem Status erschwert. Diese Maßnahmen minimieren Ausfallzeiten und erhöhen die Zuverlässigkeit der API-Integration.
Echtzeit-Überwachung und Alarme
Um Probleme schnell zu erkennen, sollten schwellenwertbasierte Alarme für 5xx-Fehlerraten eingerichtet werden. Ein 502-Bad-Gateway-Fehler lässt sich in 90 % der Fälle durch einen Neustart des Backend-Services beheben, was die Bedeutung einer schnellen Erkennung unterstreicht. Durch die kontinuierliche Erfassung und Kategorisierung von Metriken können Infrastrukturprobleme (z. B. 502, 503 oder 504) klar von Anwendungsfehlern unterschieden werden. So lassen sich gezielte Reaktionsstrategien entwickeln und Ausfallzeiten reduzieren. Diese Maßnahmen tragen nicht nur zur Systemstabilität bei, sondern optimieren auch die CUBEE API-Workflows.
sbb-itb-d35113a
Vergleich von Fehlerbehandlungsstrategien
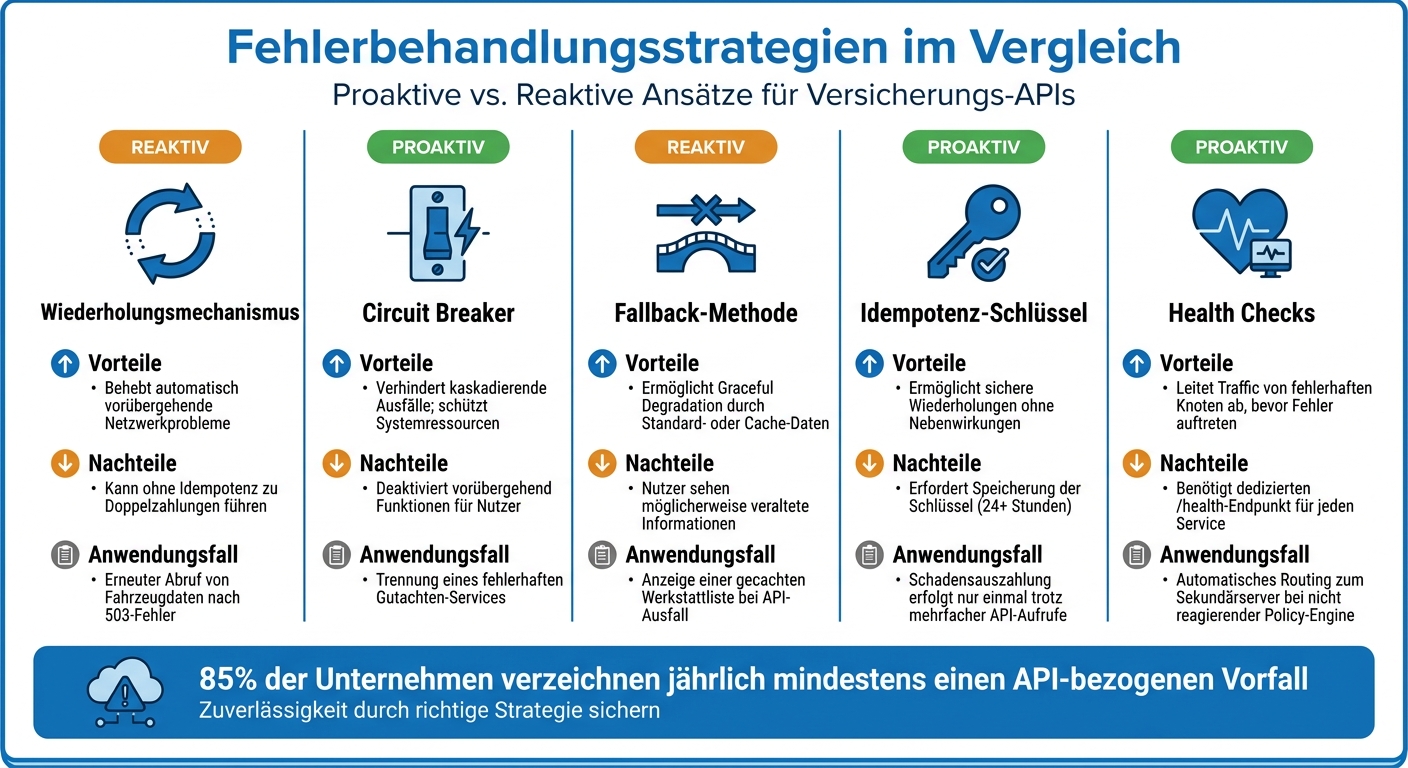
API-Fehlerbehandlungsstrategien für Versicherer: Vergleich von 5 Methoden
Hier wird ein Überblick über zentrale Fehlerbehandlungsstrategien gegeben, die entscheidend für reibungslose API-Integrationen sind.
In der API-Fehlerbehandlung werden proaktive und reaktive Ansätze unterschieden. Proaktive Methoden wie Circuit Breaker oder Health Checks zielen darauf ab, Probleme zu vermeiden, bevor sie das gesamte System beeinträchtigen. Reaktive Strategien wie Wiederholungsversuche oder Fallback-Methoden greifen ein, nachdem ein Fehler aufgetreten ist, um die Verfügbarkeit wiederherzustellen. Die folgende Tabelle fasst die wichtigsten Strategien für Versicherungsunternehmen zusammen.
Die Wahl der passenden Strategie hängt stark vom jeweiligen Anwendungsfall ab. Matthias Fischer, Software-Entwickler bei doubleSlash, erläutert:
„Wenn ein Subsystem ausfällt, blockiert ein Circuit Breaker Anfragen für eine bestimmte Zeit, andernfalls warten immer mehr Prozesse, bis sie in Timeouts laufen und dadurch den Thread-Pool erschöpfen. Dies führt zum kompletten Anwendungsausfall."
Für Versicherungsunternehmen ist eine Kombination beider Ansätze besonders wichtig. Circuit Breaker schützen die Systemstabilität, während Idempotenz-Schlüssel sicherstellen, dass Wiederholungsversuche keine doppelten Zahlungen oder Schadensansprüche auslösen. Bobur Umurzokov von API7.ai hebt hervor:
„Das Ziel von Resilienz ist es, die Anwendung nach einem Ausfall in einen voll funktionsfähigen Zustand zurückzuversetzen."
Tabelle: Fehlerbehandlungsstrategien
Die Tabelle zeigt die Vor- und Nachteile der verschiedenen Fehlerbehandlungsstrategien speziell im Versicherungsbereich.
| Strategie | Typ | Vorteile | Nachteile | Versicherungs-Anwendungsfall |
|---|---|---|---|---|
| Wiederholungsmechanismus | Reaktiv | Behebt automatisch vorübergehende Netzwerkprobleme | Kann ohne Idempotenz zu Doppelzahlungen führen | Erneuter Abruf von Fahrzeugdaten nach einem 503-Fehler |
| Circuit Breaker | Proaktiv | Verhindert kaskadierende Ausfälle; schützt Systemressourcen | Deaktiviert vorübergehend Funktionen für Nutzer | Trennung eines fehlerhaften Gutachten-Services, um das Hauptportal reaktionsfähig zu halten |
| Fallback-Methode | Reaktiv | Ermöglicht „Graceful Degradation" durch Standard- oder Cache-Daten | Nutzer sehen möglicherweise veraltete Informationen | Anzeige einer gecachten Werkstattliste bei Ausfall der Partner-API |
| Idempotenz-Schlüssel | Proaktiv | Ermöglicht sichere Wiederholungen ohne Nebenwirkungen | Erfordert Speicherung der Schlüssel (oft 24+ Stunden) | Sicherstellung, dass eine Schadensauszahlung trotz mehrfacher API-Aufrufe nur einmal erfolgt |
| Health Checks | Proaktiv | Leitet Traffic von fehlerhaften Knoten ab, bevor Fehler auftreten | Benötigt einen dedizierten /health-Endpunkt für jeden Service |
Automatisches Routing zum Sekundärserver bei nicht reagierender Policy-Engine |
Wie dies auf CUBEE API-Workflows anwendbar ist
Die zuvor beschriebenen Strategien lassen sich hervorragend auf CUBEE API-Workflows übertragen, um einen reibungslosen Datenaustausch sicherzustellen und Ausfallzeiten zu minimieren. Besonders im Bereich der digitalen Fahrzeugbegutachtung, bei der Versicherer auf kontinuierlichen Zugriff auf Gutachtendaten angewiesen sind, spielt eine präzise Fehlerbehandlung eine zentrale Rolle.
Aufrechterhaltung des unterbrechungsfreien Datenaustauschs
Ein Echtzeit-Monitoring sorgt dafür, dass Probleme bei der Gutachtenerstellung sofort erkannt werden. Beispielsweise können automatisierte Warnmeldungen – per Slack oder E-Mail – das Team rechtzeitig informieren, bevor es zu Verzögerungen im Schadensbearbeitungsprozess kommt. Dhara Kumari Rajput, Sr. Software Engineer, hebt die Bedeutung hervor:
„Monitoring and logging are essential to diagnose issues quickly and understand API usage patterns, which can inform optimization and scaling decisions."
Wiederholungsmechanismen sind ein weiterer Schlüssel, um temporäre Netzwerkprobleme zu überbrücken. Durch schrittweise verlängerte Wartezeiten zwischen erneuten Versuchen wird sichergestellt, dass die Gutachtendaten schließlich den Versicherer erreichen. Dies ist besonders bei Massenschadenereignissen, wie nach Unwettern, entscheidend. Rate-Limit-Header wie X-RateLimit-Remaining helfen dabei, das Anfragevolumen dynamisch zu steuern und so Serviceunterbrechungen zu vermeiden.
Zusätzlich ermöglicht die zentrale Protokollierung aller API-Aufrufe eine schnelle Unterscheidung zwischen isolierten Datenqualitätsproblemen – etwa einer fehlenden Fahrzeug-Identifizierungsnummer – und systemweiten Ausfällen. Dadurch können Probleme beim Datenaustausch schneller behoben werden. APIs für professionelle Automatisierungen bieten in der Regel Rate Limits von 120 bis 600 Anfragen pro Minute, um die Stabilität für Unternehmenskunden zu gewährleisten.
Diese Kombination aus Echtzeit-Monitoring, Wiederholungsmechanismen und zentraler Protokollierung garantiert eine zuverlässige Datenübermittlung – ein entscheidender Faktor für eine reibungslose Schadenbearbeitung.
Reduzierung von Ausfallzeiten bei der Gutachtenberichterstattung
Um die Verfügbarkeit der Gutachtendaten weiter zu sichern, kommen bei CUBEE auch Caching- und Circuit Breaker-Strategien zum Einsatz.
Caching-Strategien sind essenziell, um die Verfügbarkeit zu gewährleisten. Mit der stale-while-revalidate-Strategie können Versicherer sofort auf zwischengespeicherte Gutachtendaten zugreifen, während das System im Hintergrund aktualisierte Daten lädt. Alternativ stellt die stale-if-slow-Strategie sicher, dass Cache-Daten bereitgestellt werden, wenn die Live-Datenquelle langsamer reagiert.
Circuit Breaker verhindern, dass fehlerhafte API-Endpunkte das gesamte System beeinträchtigen. Wenn ein Endpunkt für Fahrzeugbegutachtungen eine hohe Fehlerrate aufweist, pausiert CUBEE automatisch die Anfragen, um den Service zu stabilisieren. Phil Wilkinson, Platform Engineer, empfiehlt:
„To navigate [rate limits], monitor and optimize your API usage, implement smart caching, and gracefully handle those 429 or 509 roadblocks."
Um Datenverluste zu vermeiden, wird eine Fehlerrate von unter 5 % angestrebt. Überschreitet die Rate diesen Schwellenwert, greifen sofortige Maßnahmen, um Datenkorruption zu verhindern. Zudem sorgen automatisierte Rollbacks im CI/CD-Prozess dafür, dass bei fehlerhaften API-Updates sofort die letzte stabile Version aktiviert wird. Dies ist besonders für mobile Gutachter im Außendienst von großer Bedeutung.
Fazit
Die beschriebenen Maßnahmen verdeutlichen, wie wichtig eine durchdachte API-Fehlerbehandlung für eine stabile Betriebsumgebung und die Einhaltung von Vorgaben ist. Elemente wie standardisierte HTTP-Statuscodes, zentrale Protokollierung, Wiederholungsmechanismen und Echtzeit-Monitoring bilden die Grundlage für eine zuverlässige Datenintegration. Insbesondere Monitoring und Logging helfen dabei, Probleme schnell zu identifizieren und API-Nutzungsmuster zu analysieren, was fundierte Entscheidungen zu Optimierung und Skalierung ermöglicht.
Fehlermeldungen müssen so gestaltet sein, dass sie keine sensiblen Informationen preisgeben, die potenziell von Angreifern missbraucht werden könnten. Gleichzeitig sollten sie Entwicklern die nötigen Hinweise geben, um Probleme effizient zu lösen. Abhishek Anand, Associate bei Cognizant, betont dabei:
"In case of API failure, you also need to take care of proper re-direction to the proper screen."
Diese Prinzipien verbessern nicht nur die Fehlerbehandlung, sondern gewährleisten auch einen reibungslosen Datenaustausch innerhalb der CUBEE API-Workflows. Versicherer, die diese Ansätze konsequent anwenden, profitieren von kürzeren Bearbeitungszeiten, weniger Supportanfragen und einer höheren Verfügbarkeit ihrer Systeme. Angesichts der Tatsache, dass 85 % der Unternehmen jährlich mindestens einen API-bezogenen Vorfall verzeichnen, kann eine robuste Fehlerbehandlung den entscheidenden Unterschied zwischen einem stabilen Betrieb und teuren Ausfällen ausmachen.
Die konsequente Anwendung dieser Strategien stellt sicher, dass Versicherer auch bei wachsenden Herausforderungen flexibel bleiben und ihren Kunden weiterhin zuverlässig zur Seite stehen können.
FAQs
Welche API-Fehler sollte ich automatisch retryen?
Automatische Wiederholungsversuche sollten bei Netzwerkfehlern, Zeitüberschreitungen sowie Ratenbegrenzungs- und Kontingentfehlern erfolgen. Solche Fehler sind häufig vorübergehend und lassen sich oft durch einen erneuten Versuch beheben.
Wie vermeide ich DSGVO-Risiken in API-Logs?
Um Risiken im Zusammenhang mit der DSGVO zu vermeiden, sollten personenbezogene Daten niemals ungeschützt in API-Logs gespeichert werden. Verschlüsseln Sie sensible Informationen, beschränken Sie die Protokollierung auf das Nötigste und kontrollieren Sie den Zugriff streng. Planen Sie regelmäßige Überprüfungen ein und stellen Sie sicher, dass Logs so konfiguriert sind, dass personenbezogene Daten automatisch anonymisiert oder gelöscht werden. Diese Schritte helfen dabei, DSGVO-Vorgaben einzuhalten und Datenschutzverletzungen vorzubeugen.
Wann sind Idempotenz-Schlüssel wirklich notwendig?
Idempotenz-Schlüssel spielen eine zentrale Rolle, wenn es darum geht, doppelte Vorgänge bei API-Interaktionen zu vermeiden. Besonders bei mehrfachen oder verzögerten Anfragen sorgen sie dafür, dass Datenfehler und Inkonsistenzen vermieden werden. So bleibt die Kommunikation zwischen Systemen stabil und verlässlich.
Verwandte Blogbeiträge
- 5 häufige Schwachstellen in digitalen KFZ-Datenplattformen
- API-Schwachstellen in Standortsystemen verstehen
- API-Entwicklung für KFZ-Gutachten: Ein Leitfaden
- Best Practices für API-Dokumentation in Versicherungs-APIs