
Echtzeit-Datenintegration ist der Schlüssel, um Versicherungsprozesse schneller, effizienter und kundenfreundlicher zu gestalten. Manuelle Schritte und Verzögerungen gehören der Vergangenheit an. Automatisierte Workflows, die auf Echtzeit-Daten basieren, ermöglichen eine zügige Schadenbearbeitung, präzise Entscheidungen und eine verbesserte Kundenerfahrung.
Die wichtigsten Schritte:
- Workflows analysieren und Datenbedarf klären: Schwachstellen erkennen und Datenquellen kategorisieren.
- Systemarchitektur entwickeln: APIs, Event-Streaming und ein einheitliches Datenmodell schaffen.
- Umsetzung starten: Prozesse wie Schadenbearbeitung und Betrugserkennung priorisieren.
- Überwachung und Optimierung: Performance messen, Engpässe beheben und Systeme skalieren.
Ein praktisches Beispiel:
Die CUBEE Sachverständigen AG liefert maschinenlesbare Kfz-Gutachten direkt in Versicherungs-Workflows. Das Ergebnis? Schnellere Entscheidungen und geringere Kosten. Laut McKinsey können Versicherer so bis zu 30 % Kosten sparen und Bearbeitungszeiten von 7–10 Tagen auf 24–48 Stunden reduzieren.
Echtzeit-Datenintegration ist keine Option, sondern eine Notwendigkeit, um wettbewerbsfähig zu bleiben.
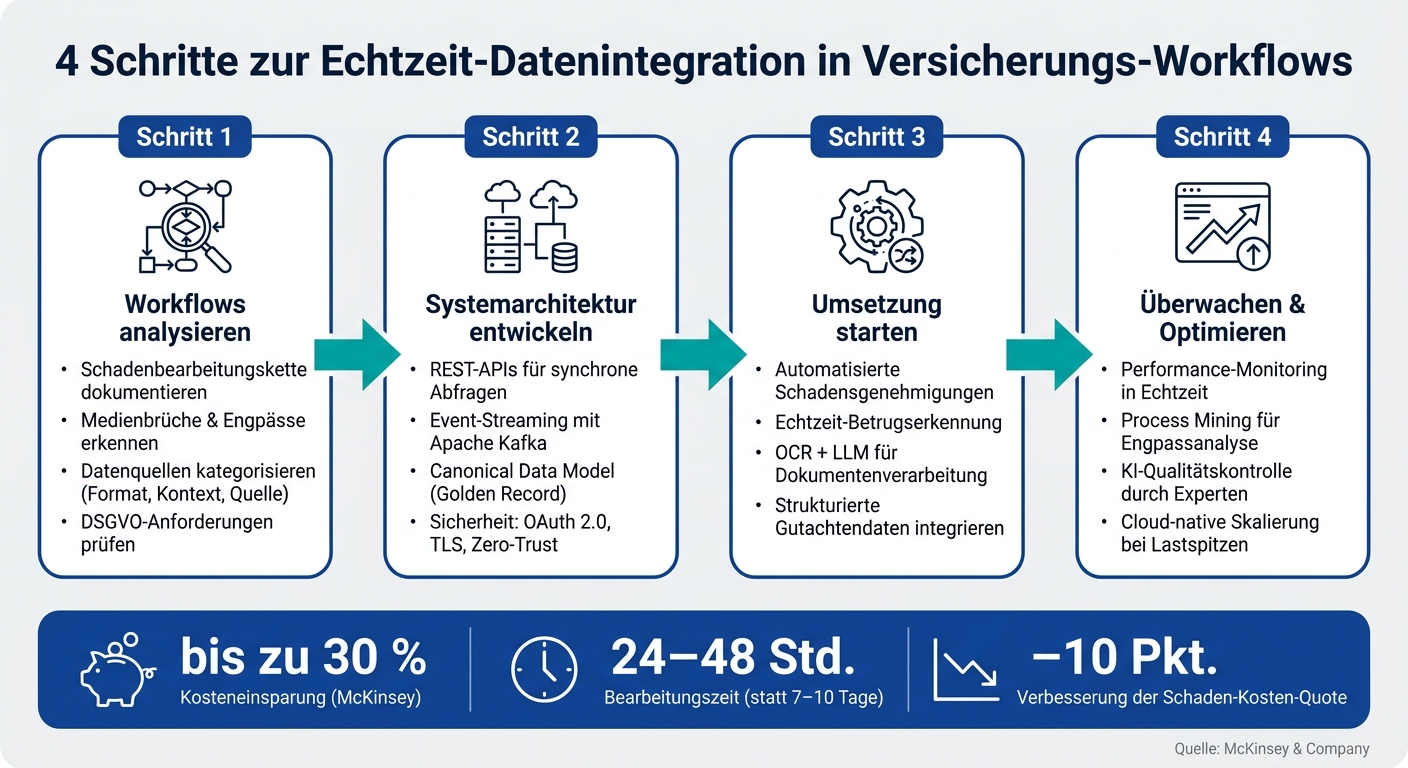
4 Schritte zur Echtzeit-Datenintegration in Versicherungs-Workflows
Schritt 1: Bestehende Workflows analysieren und Datenbedarf definieren
Um Echtzeit-Daten erfolgreich in bestehende Prozesse zu integrieren, ist eine präzise Analyse der Workflows unverzichtbar. Bevor die technische Umsetzung beginnt, sollten zunächst Schwachstellen und Engpässe identifiziert werden. Dieser Schritt ist eher analytisch als technisch.
Versicherungs-Workflows im Detail verstehen
Der erste Schritt besteht darin, die gesamte Schadenbearbeitungskette zu dokumentieren – von der Schadensmeldung bis zur Auszahlung. Dabei gilt es, jeden Prozessschritt zu erfassen und Medienbrüche zu erkennen. Diese treten oft auf, wenn manuelle Formate wie PDFs, E-Mails oder Fotos mit strukturierten, digitalen Daten kombiniert werden. Solche Brüche sind ideale Ansatzpunkte für die Integration von Echtzeit-Daten.
Ein typisches Problem: Ein Sachbearbeiter überprüft manuell, ob eine Werkstattrechnung mit der gemeldeten Unfallsituation übereinstimmt – etwa ob das Lackieren eines Stoßfängers plausibel ist.
„Die Datenextraktion bildet die Grundlage für alle nachgelagerten Prüf-, Entscheidungs- und Steuerungsprozesse. Fehlt hier die nötige Struktur und Einordnung, geraten selbst digital gestartete Prozesse schnell ins Stocken." – Philipp Schäfer, Managing Director, Eucon Digital
Datenquellen analysieren und kategorisieren
Nach der Workflow-Analyse folgt die systematische Erfassung der relevanten Datenquellen. Eine klare Kategorisierung hilft, den Fokus auf die wichtigsten Daten für die Echtzeit-Integration zu legen:
| Klassifikationskriterium | Beschreibung | Priorität für Echtzeit-Integration |
|---|---|---|
| Datenformat | Unstrukturiert (z. B. PDF, Bilder) vs. strukturiert | Hoch – Strukturiert bevorzugt, da es automatisierte Entscheidungen erleichtert |
| Kontextrelevanz | Daten, die die Plausibilität eines Schadens prüfen | Hoch – Entscheidend für automatisierte Entscheidungen |
| Quellentyp | Extern (z. B. Werkstätten, Gutachter) vs. intern (z. B. CRM, Datenbanken) | Mittel – Externe Quellen bergen oft Medienbrüche |
| Verarbeitungstiefe | Einfache Extraktion (z. B. Namen, Daten) vs. semantische Analyse | Hoch – Semantische Analyse ermöglicht Automatisierung |
Externe Datenquellen, wie maschinenlesbare Gutachten von Anbietern wie der CUBEE Sachverständigen AG, bieten enormes Potenzial. Oft werden diese Daten noch manuell ins System übertragen, was vermeidbare Verzögerungen verursacht.
Technische und regulatorische Anforderungen einbeziehen
Sobald die relevanten Datenquellen definiert sind, müssen technische und rechtliche Rahmenbedingungen berücksichtigt werden. Besonders der Datenschutz und die Einhaltung der DSGVO spielen bei der Verarbeitung von Kundendaten, Schadenfotos oder Werkstattrechnungen in Echtzeit eine zentrale Rolle. Aspekte wie Speicherort, Zugriffsrechte und Löschfristen sind dabei essenziell.
Auch die Integration in bestehende Kernsysteme kann herausfordernd sein, da viele dieser Systeme historisch gewachsen sind und moderne API-Standards oft nicht unterstützen. Wird Telematik und KI eingesetzt, sollten die Ergebnisse regelmäßig von Experten geprüft werden, um potenzielle Fehler in der Automatisierung zu minimieren. Dies schützt vor fehlerhaften Entscheidungen und erhöht die Prozesssicherheit.
sbb-itb-d35113a
Schritt 2: Systemarchitektur für die Echtzeit-Integration entwerfen
Nachdem die Workflows analysiert und die Datenquellen klassifiziert wurden, geht es jetzt an den technischen Kern: die Architektur. Sie ist entscheidend dafür, ob die Echtzeit-Integration den gewünschten reibungslosen Datenaustausch ermöglicht. Hier sind einige konkrete Ansätze, die technische Lösungen greifbar machen.
Das passende Integrationsmuster finden
Die Wahl des richtigen Integrationsmusters hängt stark vom jeweiligen Prozess ab. Für direkte Abfragen, wie etwa das Einholen eines Gutachtens zu einem laufenden Schadensfall, eignen sich synchrone REST-APIs hervorragend. Sie liefern sofortige Antworten und sind ideal für solche Szenarien.
Anders sieht es bei Prozessen aus, die durch Ereignisse angestoßen werden. Hier macht eine Event-Driven Architecture (EDA) mit Tools wie Apache Kafka den Unterschied. Ein Beispiel: Wird ein neuer Schadensfall gemeldet, kann Kafka dies als Ereignis behandeln, das gleichzeitig mehrere Systeme aktiviert – von der Schadensbearbeitung über die Betrugserkennung bis hin zur Kundenkommunikation. Das geschieht in Millisekunden, statt auf nächtliche Batch-Läufe zu warten.
„Event-Streaming... kann das Zentrum einer datengetriebenen Verarbeitung in den Kernsystemen eines Versicherers bilden." – Martin Barthel, Head of Product Development, adesso insurance solutions
Tatsächlich setzen 80 % der Fortune-100-Unternehmen und alle zehn führenden Versicherungskonzerne weltweit auf Apache Kafka für Event-Streaming. Für Versicherer, deren gewachsene Kernsysteme keine modernen APIs unterstützen, bietet sich Change Data Capture (CDC) an. Diese Methode wandelt Datenbankänderungen direkt in Event-Pipelines um – ohne den Quellcode der alten Systeme verändern zu müssen. Das schafft eine solide Basis für die Entwicklung eines einheitlichen Datenmodells.
Einheitliches Datenmodell entwickeln
Wenn Daten aus unterschiedlichen Quellen wie der CUBEE Sachverständigen AG, Werkstattrechnungen und internen CRM-Systemen zusammengeführt werden, stehen Sie oft vor einem Problem: Jede Quelle liefert Daten in einem anderen Format. Hier kommt ein Canonical Data Model ins Spiel. Es fungiert als gemeinsame Sprache, die alle Systeme verstehen.
Eine „Golden Record"-Strategie über einen zentralen Operational Data Store (ODS) sorgt zusätzlich dafür, dass stets die aktuellste und konsistenteste Version eines Datensatzes verfügbar ist. Alle nachgelagerten Systeme greifen auf diese zentrale Quelle zu. Das verhindert widersprüchliche Datenstände und ermöglicht eine zuverlässige, automatisierte Entscheidungsfindung. Dabei darf die Sicherheitsarchitektur nicht außer Acht gelassen werden.
Sicherheit für APIs und Datentransfers gewährleisten
Echtzeit-Datenströme müssen abgesichert sein – hier kommen Technologien wie OAuth 2.0, TLS-Verschlüsselung und ein zentral gesteuertes API-Gateway ins Spiel. Zusätzlich wird das Zero-Trust-Prinzip immer wichtiger: Jede Anfrage wird individuell geprüft, um maximale Sicherheit zu gewährleisten.
Für die Einhaltung der DSGVO und der DORA-Verordnung ist ein lückenloses Audit-Trail unverzichtbar. Jede Änderung, jeder API-Aufruf und jede Verarbeitung von Daten muss revisionssicher protokolliert werden. So wird nicht nur die Sicherheit, sondern auch die Compliance sichergestellt.
Schritt 3: Echtzeit-Datenverarbeitung implementieren
Jetzt kommt der entscheidende Moment: Die praktische Umsetzung. Hier zeigt sich, ob die zuvor entwickelte Architektur hält, was sie verspricht. Der Fokus liegt darauf, mit den Anwendungsfällen zu starten, die den größten Nutzen bringen.
Mit den wichtigsten Anwendungsfällen starten
Nicht alle Prozesse profitieren gleichermaßen von Echtzeit-Daten. Beginnen Sie dort, wo die Wirkung am größten ist. Beispiele wie automatisierte Schadensgenehmigungen und Echtzeit-Betrugserkennung sind ideale Startpunkte. Diese lassen sich durch regelbasierte Entscheidungs-Engines und Machine-Learning-Modelle nahtlos in bestehende Workflows integrieren. Besonders bei Schadensfällen wird der direkte Einfluss auf die Kundenzufriedenheit und die Betriebskosten sofort sichtbar.
Für die Umsetzung solcher Use Cases ist eine klar definierte API-Strategie unerlässlich.
APIs entwickeln und Workflows optimieren
Ein häufiges Hindernis in modernen Versicherungsprozessen sind Dokumente in Freitext- oder Bildformaten. Hier kommen APIs ins Spiel, die OCR-Technologien (Optical Character Recognition) mit Large Language Models (LLMs) kombinieren. Diese Systeme können nicht nur Texte erkennen, sondern auch deren Inhalte verstehen. So wird es beispielsweise möglich, eine Reparaturposition auf einer Werkstattrechnung automatisch einem spezifischen Unfalltyp zuzuordnen.
Da LLMs gelegentlich ungenaue Ergebnisse liefern, sollte ein Hybrid-Validierungsprozess integriert werden. Dieser kombiniert automatisierte Prüfungen mit manuellen Kontrollen für kritische Entscheidungen. Wichtig ist auch, dass APIs nicht nur Rohdaten liefern, sondern Kontextinformationen bereitstellen. Ein Beispiel: Gehört eine Lackierarbeit zum aktuellen Schaden oder zu einem früheren Vorgang?
„LLMs bringen Verständnis, Kontext, Verknüpfung und Geschwindigkeit in die Datenverarbeitung." – Eucon Digital
Integration von CUBEE-Daten in Schaden- und Vertragsprozesse
Auf Basis der entwickelten APIs ermöglicht die Einbindung strukturierter Daten eine durchgängige Prozessautomatisierung. Über standardisierte API-Schnittstellen können Gutachtenberichte, Fahrzeugfotos und Bewertungsergebnisse der CUBEE Sachverständigen AG direkt in das Schadenmanagementsystem übertragen werden. Medienbrüche und manuelle Zwischenschritte entfallen vollständig.
CUBEE stellt strukturierte Schadensdaten unmittelbar nach Abschluss einer Begutachtung bereit. Dadurch können nachgelagerte Systeme – von der Reservestellung bis zur Auszahlungsentscheidung – sofort reagieren. Die eingehenden Daten werden in das einheitliche Datenmodell aus Schritt 2 überführt, was eine konstant hohe Datenqualität sicherstellt. Dabei spielt es keine Rolle, ob die Gutachten als PDF, Foto oder strukturierter Bericht vorliegen.
Schritt 4: Echtzeit-Datenintegration überwachen, optimieren und skalieren
Sobald das System läuft, zeigt sich, wie zuverlässig die Echtzeit-Daten fließen und ob die Prozesse wie geplant optimiert werden. Hier beginnt die Phase der Überwachung, Verbesserung und Anpassung.
Performance-Monitoring einrichten
Die in Schritt 2 entwickelte Event-Streaming-Architektur dient gleichzeitig als Grundlage für ein effektives Monitoring. Jeder Prozessschritt wird als messbares Ereignis erfasst. Eine Reporting-Komponente wird als zusätzlicher Consumer integriert, der die Daten in Echtzeit visualisiert – ohne den Hauptworkflow zu beeinträchtigen.
Bei KI-gestützten Prozessen, wie der automatisierten Analyse von Gutachten, ist eine KI vs. Mensch in der Qualitätskontrolle unverzichtbar. Experten prüfen stichprobenartig, ob die KI plausible, aber fehlerhafte Ergebnisse liefert. Diese Kontrolle ist essenziell, um eine hohe Datenqualität sicherzustellen. Durch diese Überwachung können Prozesse kontinuierlich verbessert und flexibel an Lastspitzen angepasst werden.
Prozesse mit Analytics kontinuierlich verbessern
Mit Process Mining lassen sich Engpässe identifizieren, die im Alltag oft unbemerkt bleiben. Ein häufiger Schwachpunkt sind sogenannte Medienbrüche – etwa wenn unstrukturierte Daten wie PDFs, E-Mails oder Fotos nicht maschinell verarbeitet werden können. Solche Brüche führen zu zusätzlichem manuellem Aufwand.
Hier kommt die semantische Analyse ins Spiel, die unstrukturierte Informationen effizienter nutzbar macht. Feedback-Schleifen aus dem laufenden Betrieb tragen dazu bei, KI-Modelle schrittweise zu verbessern. Langfristig kann so eine autonome Schadenbearbeitung Realität werden.
Systeme für Lastspitzen skalieren
Die in Schritt 2 entwickelte Architektur wird durch kontinuierliche Optimierung und Anpassung an schwankende Datenlasten erweitert.
Versicherungssysteme erleben selten eine gleichmäßige Auslastung. Großschadenereignisse wie Hagelstürme oder Massenunfälle können die Datenmenge in kürzester Zeit drastisch erhöhen. Cloud-native Architekturen bieten hier eine Lösung: Sie ermöglichen es, die Infrastruktur während des laufenden Betriebs automatisch hochzuskalieren, ohne das System offline nehmen zu müssen.
Durch entkoppelte Komponenten können Updates oder der Austausch einzelner Systeme durchgeführt werden, ohne den Gesamtprozess zu stören. Skalierungsregeln sollten sowohl für planbare als auch für unerwartete Lastspitzen definiert sein.
Fazit: Die wichtigsten Schritte zur Echtzeit-Datenintegration in der Versicherung
Die Umsetzung der Echtzeit-Datenintegration in der Versicherungsbranche lässt sich in vier zentrale Schritte gliedern: Analyse der bestehenden Prozesse und Datenanforderungen, Entwicklung einer geeigneten Architektur, Umsetzung erster Anwendungsfälle (wie z. B. automatisierte Kfz-Schadenregulierung) und schließlich Überwachung, Optimierung und Skalierung.
Ein Beispiel für praktische Unterstützung bietet die CUBEE Sachverständigen AG. Mit einem Netzwerk von Container-Standorten in Deutschland und Europa sowie mobilen Gutachtern erstellt CUBEE strukturierte und digital verfügbare Kfz-Gutachten. Diese decken alles ab – von der Schadensbewertung bis zur Bewertung von Oldtimern. Die Gutachtendaten werden über standardisierte Schnittstellen direkt in die Schaden-Workflows der Versicherer integriert, was ein effizientes Straight Through Processing ermöglicht. Dieser digitale Ansatz sorgt für schnellere Prozesse und schafft mehr Transparenz.
Laut einer Analyse von McKinsey können Versicherer durch Echtzeit-Datenintegration in Kernprozessen bis zu 30 % der Kosten einsparen und die Schaden-Kosten-Quote um bis zu 10 Prozentpunkte verbessern. Die Bearbeitungszeiten für Kfz-Schäden können dabei erheblich verkürzt werden: Schäden, die früher 7–10 Tage dauerten, lassen sich oft innerhalb von 24–48 Stunden abschließen. Der Einstieg gelingt am besten durch einen klar definierten Pilotversuch, dessen Vorteile in der Praxis schnell sichtbar werden.
Diese Transformation ist mehr als nur ein IT-Projekt – sie ist eine strategische Entscheidung, die nicht nur Prozesse beschleunigt, sondern auch die Kundenzufriedenheit steigert und Kosten senkt.
FAQs
Welche Echtzeit-Use-Cases bringen in der Schadenbearbeitung den größten ROI?
Die Automatisierung manueller Prozesse revolutioniert die Schadenbearbeitung und steigert den ROI erheblich. Besonders hervorzuheben sind folgende Ansätze:
- Automatisierte Datenerfassung: Mithilfe von OBD-II-Schnittstellen und Telematiksystemen können präzise Unfallrekonstruktionen erstellt werden. Das führt nicht nur zu einer schnelleren Klärung von Streitfällen, sondern minimiert auch Unklarheiten.
- KI-gestützte Schadensanalyse: Künstliche Intelligenz ermöglicht es, Schadensberichte innerhalb von Minuten zu erstellen – ein Prozess, der früher Tage in Anspruch nahm.
- Condition-Monitoring für Flotten: Durch kontinuierliche Überwachung des Fahrzeugzustands wird die Effizienz von Flotten gesteigert und potenzielle Probleme frühzeitig erkannt.
- Betrugserkennungssysteme: Intelligente Datenabgleiche helfen dabei, betrügerische Ansprüche zu identifizieren und Verluste zu reduzieren.
Die CUBEE Sachverständigen AG setzt auf digitalisierte Prozesse und mobile Gutachter, um diese Technologien in der Praxis zu integrieren und die Schadenbearbeitung effizienter zu gestalten.
Wie integriere ich Echtzeit-Daten in Altsysteme ohne großen Aufwand?
Standardisierte Schnittstellen wie APIs sind der Schlüssel, um Echtzeit-Daten nahtlos in bestehende Altsysteme zu integrieren. Sie ermöglichen einen automatisierten Datenaustausch zwischen verschiedenen Plattformen und Systemen, wie etwa Gutachter-Software, Versicherungsplattformen und Werkstattsystemen.
Ein weiterer nützlicher Ansatz sind Webhooks, die Prozesse wie Statusmeldungen oder Archivierungen automatisieren können. Das spart Zeit und sorgt für einen reibungslosen Ablauf.
Ein Beispiel aus der Praxis: Die CUBEE Sachverständigen AG setzt auf digitale Lösungen, um Fahrzeugdaten direkt in ihre Workflows zu integrieren. Das reduziert nicht nur den Bedarf an manuellen Eingaben, sondern steigert auch die Effizienz in der Schadensregulierung erheblich.
Wie gewährleiste ich DSGVO/DORA-Compliance und Echtzeit-Audit-Trails?
Um die Anforderungen der DSGVO und DORA zu erfüllen und gleichzeitig Echtzeit-Audit-Trails sicherzustellen, sind gut durchdachte technische und organisatorische Maßnahmen unverzichtbar. Hier einige wichtige Schritte:
- Analyse und Dokumentation der Datenflüsse: Ein klarer Überblick über alle Datenbewegungen innerhalb und außerhalb des Unternehmens ist entscheidend.
- Ende-zu-Ende-Verschlüsselung und Pseudonymisierung: Diese Maßnahmen schützen sensible Daten effektiv vor unbefugtem Zugriff.
- Strenge Zugriffskontrollen: Nur autorisierte Personen sollten auf bestimmte Daten zugreifen können.
- Double-Opt-In-Verfahren: Dieses Verfahren stellt sicher, dass Nutzer aktiv und nachweisbar in die Datenverarbeitung einwilligen.
Die CUBEE Sachverständigen AG bietet hierbei wertvolle Unterstützung. Mit digitalisierten Prozessen, zentralisierter Datenauswertung und automatisierten Löschfristen hilft sie Unternehmen, ihre Compliance effizient zu gestalten. Ergänzend dazu sind regelmäßige Sicherheitsupdates und IT-Audits unerlässlich, um die IT-Infrastruktur sowohl sicher als auch rechtskonform zu halten.